
June 08, 2021
Apache Spark machine learning for predictive maintenance
Author:

Data scientist
Reading time:
23 minutes
Apache Spark [1] is a powerful engine for processing large datasets efficiently. Apache Spark Machine Learning Library (Spark MLlib [2]) can be used to build scalable machine learning pipelines.
We’ll explore Spark’s capability to perform supervised machine learning tasks in the context of predictive maintenance. The goal of a predictive maintenance algorithm is an estimation of the optimal maintenance time based on the condition of the equipment. Predictive maintenance is important in numerous domains such as manufacturing, transportation, power plants, and the oil industry.
Predictive maintenance with Apache Spark
Machines and vehicles remain an asset only as long as they are functional. Whether it is in a factory, airplane, car, or windmill, the subsystems and components require maintenance for the whole equipment to continue being an asset.

Maintenance can be performed using one of the 3 possible strategies:
- Reactive (corrective) maintenance lets the machine run until failure and then repairs are made to get the equipment back to its operational state. This approach makes sense only in some very simple, non-critical equipment like a light bulb. Otherwise, letting a breakdown happen is too dangerous in terms of safety and also expensive – replacement or repair of a broken part is more costly than a just-in-time repair, there’s a risk that the broken part damages other elements, and prolonged downtime has a high cost (e.g. power outages).
- Preventive maintenance strategy involves regular, scheduled maintenance. This approach is still costly because the machine must be maintained frequently to avoid breakdown and we always risk scheduling maintenance too late which can result in the equipment failure.
- Predictive maintenance [3] methods evaluate the condition of equipment to predict when maintenance should be performed. Equivalently, one must predict the failure time because optimal maintenance time is right before the failure. This way, we can minimize the downtime and costly repair that a breakdown incurs, while maximizing the equipment lifetime and save money on checkups that would turn out to be scheduled too early.

Plots comparing the maintenance strategies are a reconstruction from this predictive maintenance video by Matlab.
The predictive maintenance approach is superior, but it entails a large initial investment in sensors collecting data, data infrastructure, subject matter experts, and IT experts (software developers, data engineers, and data scientists). These costs can be large, so predictive maintenance solutions are worthy of developing and deploying mainly for expensive and time-critical systems.
A predictive maintenance solution is a process that is similar to other advanced analytics scenarios. At first, the raw data must be collected. Then, this data must be analyzed, cleaned, validated, and preprocessed into useful features that indicate the equipment’s condition. Then a predictive model can be trained on the feature dataset and deployed to serve in predicting failures. A constant evaluation of the whole process is required to ensure the precision of the predictions. Domain experts’ opinions and monitoring metrics of the deployed model are invaluable feedback signals to ensure the predictive maintenance system works properly.
Read more about Predictive Models Performance Evaluation.
Data-driven predictive maintenance
The type of predictive maintenance that is described in this article is called data-driven, as opposed to model-driven predictive maintenance that is mainly based on prior knowledge and physical models. In data-driven predictive maintenance, data is the most important factor that conditions whether the predicted failures will be accurate and useful.
No one can determine beforehand the exact amount of data required for a good predictive model. The sufficient data volume is dependent on many aspects of the concrete use case, such as:
- The complexity of the equipment and the environment it operates in
- The nature of the potential failure and how often it occurs
- The number, type, and quality of used sensors
- The selected learning model
- The desired time-granularity and accuracy of the predictions
Still, even without knowing these aspects, it’s safe to assume that a large quantity of data is required. The data must contain many instances of the same machine, with numerous run-to-failure historic profiles.
For example, if all the available data is from 2 instances of the machine, with a total of few past failures, then the model won’t be able to learn enough patterns to predict failures reliably. In such cases, one can either wait and collect more data, get data from the outside (perhaps from the equipment producer or other organization using the same equipment) or switch to a hybrid predictive maintenance approach that relies on both data and predefined physical model.
We established that the data pipeline that supports the predictive maintenance predictions ideally has a large amount of data. To efficiently handle big data, the system should feature distributed data storage and distributed processing in a cluster environment. Apache Spark ML running on a Hadoop or Kubernetes cluster is an excellent candidate for such a big data application. Apache Spark machine learning can ingest a huge amount of data from various sources, leverage Spark SQL and DataFrame API for efficient, distributed data wrangling and cleaning, and then Apache Spark machine learning library can be used for the feature engineering and development of the Machine Learning model.
Predictive maintenance algorithm goal
The two most common types of tasks in supervised machine learning are classification and regression, where the objective is predicting labels based on the data. The objective of predictive maintenance can be framed either as a regression or classification problem:
- Regression task: when will it fail? The goal is to predict the remaining useful lifetime (RUL) of the equipment, usually defined as the remaining number of days, engine cycles, or distance. A target variable is a real number.
- Classification task: will it fail? The goal is to predict whether the failure will occur within a specified time window. This can be either a binary classification task for a single time window (will the equipment fail in the next N days?) or a multi-class classification task for several time windows (will the equipment fail in the next 3 days, 5 days, 10 days?)
The regression formulation is more informative. Probably everyone would prefer to know the exact timestamp of the predicted failure rather than a time window within which it is estimated to happen.
Yet, the RUL prediction is also more difficult for the learning algorithm. If you can provide a large amount of data then you can opt for the RUL predictions as the model should be able to capture the hidden failure patterns and be provide accurate RUL predictions. However, if the number of monitored instances of the machine is low and/or you don’t have that many sensors, then in all likelihood there won’t be enough data to estimate RUL reliably. In such cases, the classification formulation should be preferred.
The regression and classification tasks are solved with supervised machine learning algorithms and require the ground truth labels such as RUL values. A completely different approach that doesn’t require labels is using unsupervised machine learning algorithms. In particular, predictive maintenance could be addressed as an anomaly detection problem.
Sometimes you have to formulate predictive maintenance as an unsupervised problem, for example, if the full run-to-failure history is unavailable and you only have data from the operational stage of the equipment and/or the degradation stage, without the information about the failures. In this article, only the supervised problem approach will be explored.
Temporal aspect in predictive maintenance data
RUL estimation is essentially a type of multivariate time-series problem because sensors collect information about equipment over time. For example, a sensor measures temperature at every engine cycle. These sensor readings are usually correlated, i.e. temperature at the current cycle depends on the temperature in the past cycles. For instance, a deteriorating machine could have a failing trend of some condition indicator before failure. Leveraging this temporal aspect has a large potential to obtain high-quality RUL estimates.
A simplistic approach would presume that data points are not correlated across time steps, i.e. information about past cycles of the machine is not taken into account and single-cycle information is used at the time. This is a standard framework for supervised machine learning, where all the features are considered static in nature (e.g. weight or height of an object). Although simplistic, it’s still worthwhile to predict RUL based solely on the current level of equipment.
A sensible intermediary approach is to use time window processing and prepare features that capture the preceding measurements. This way, we extend the features that describe the current state with features that describe previous states in the chosen time window. Possibly, aggregates of past measurements in the time window can be used instead of raw past measurements or in addition to them. This solution has the advantage of exploiting the temporal aspect of data while allowing the convenient use of supervised Machine Learning algorithms.
Apache Spark Machine Learning Library (MLlib)
Spark has rich capabilities to perform advanced analytics. In particular, Apache Spark includes the MLlib library that can be used to build end-to-end machine learning pipelines. The default data structure used in the Apache Spark Machine Learning library is DataFrame from Spark SQL module, hence Machine Learning applications integrate well into Apache Spark ML applications that potentially leverage complex structured queries and stream processing.
Apart from using the standard DataFrame, Apache Spark Machine Learning library has a low-level data type Vector which is a required format for features in the DataFrame. All learning models require that features are concatenated into a single column that is a Vector of Doubles. Typical dense vectors are implemented with classic numpy.ndarray arrays. Though we often obtain vectors using high-level operations, creating a vector by hand can be as easy as:

In the Apache Spark Machine Learning library, a typical way to define an algorithm workflow is as a Pipeline, which is a sequence of PipelineStages to be executed. Each stage is either a Transformer or Estimator:
- Transformers [4] convert input DataFrame into another one by appending column(s). This is either a feature transformer or a fitted model that appends prediction labels
- Estimators [5] are learning algorithms to be trained on the input DataFrame. A fitted model is a “trained transformer” that can be used to generate predictions
A Pipeline itself is an estimator and we can provide it with a DataFrame to produce a PipelineModel, which in turn is a trained transformer that can produce predictions. This way, a pipeline encapsulates several operations that can be conveniently launched on some data and then used for predictions.
Another benefit of pipelines is that we can tune hyperparameters of an entire pipeline at once (featurization, model architecture & learning) and select the best model for the task.
The typical scenario to use Apache Spark Machine Learning library (MLlib) is when you have a lot of data. Apache Spark ML can help you process the dataset and train the model faster with the use of distributed processing. In comparison, single-machine packages like scikit-learn would fail to handle a large quantity of data that doesn’t fit in a single machine.
Spark for predictive maintenance
A large chunk of work towards a predictive system is processing raw data, rather than crafting features or tuning the predictive model. This includes tasks such as data analysis, wrangling, validation, and cleaning. Concrete examples include joining tables from various data sources, reshaping tables, removing errors, bringing variables to the same value format and column type.
Spark SQL is a module for structured data processing that can be successfully used for these types of tasks. As mentioned earlier, Apache Spark Machine Learning library and Spark SQL are compatible and both rely on the same DataFrame structure, hence one can do initial data processing tasks in Spark SQL and then develop a Machine Learning solution with Apache Spark MLlib. In this article, we focus on the Machine Learning part.
For the sake of the article, a tiny illustrative synthetic dataset was created:

Feature Development
The dataset consists of only 2 instances of the same machine (unit_id 0 and 1) with the first one having failure after 44 cycles and the second one failing after 39 cycles. The label column is the remaining useful time. A typical dataset would contain many machines of the same type (e.g. unit_id going up to tens), more raw features, and longer run-to-failure history (e.g. rows of hundreds of cycles). You can see the code gist that generated this DataFrame here.
Raw data may not provide the best features for the Machine Learning job. To accurately predict an upcoming failure of equipment, the model requires data with features in a suitable form that represents the state of the equipment well and in the appropriate format for a given algorithm. You need to obtain features that are good condition indicators, i.e. they discriminate between the healthy and faulty operation of the equipment. Apache Spark ML is a great candidate for feature-related preprocessing because its MLlib module provides many functions to work with features in a distributed fashion, on a big amount of data.
Bucketing preprocessing
The technique of data binning (bucketing) turns a single continuous feature into a categorical one by splitting the data into bins. The end result is still a single column, but with modified feature space. Overall, bucketing entails information loss due to discretization and must be used carefully, but in some scenarios, it can reduce overfitting and boost the accuracy of the model.
In a predictive maintenance system, continuous raw variables may often be noisy and have a skewed distribution. The temperature and pressure measurement of some components can be highly skewed because most of the data points are concentrated around the optimal operational range. There are relatively few readings outside this range, which makes these areas underrepresented in the sample and introduces a skew.
For instance, sensors may have very sparse measurements of temperature below 10*C, which results in poor statistical power towards the prediction of equipment’s failure state that is correlated with low temperatures. Using bucketing, all the measurements below 10*C could be grouped into a single-valued class (interval), which wouldn’t be sparsely populated. Also, the numerous typical temperature values would be merged into a common bin, which is a form of data regularization and can make the model generalize better.
Typically, there’s no prior knowledge about the boundaries of intervals (e.g. the mentioned 10*C boundary), but this can be resolved by using the quantile boundaries, i.e. the Quantile Binning technique. This way, a relatively uniform representation is obtained where each bin has a similar number of counts (see the illustration below).

Figure source – Google’s ML course [6]. Quantile bucketing gives each bucket about the same number of cars.
In Apache Spark ML, one can use the bucketing via the Bucketizer transformer [7] and quantile bucketing using the QuantileDiscretizer transformer [8]. Below, you see an example of using the quantile bucketing in Spark:

Now, the df_binned DataFrame has the temp_binned column appended:

Additionally, we can also inspect the histograms:
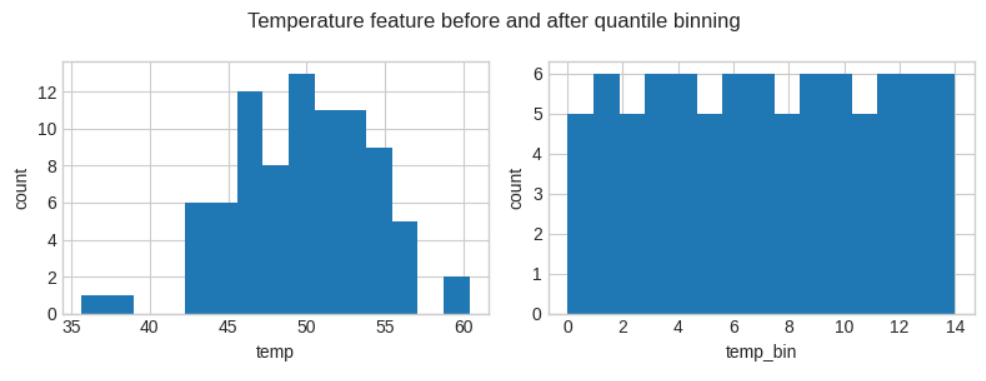
Before the transformation, the temperatures below 40*C and around 60*C were underrepresented, while after quantile bucketing each bin has a similar number of samples.
Interaction transformer
Systems that require maintenance are usually complex and display various dependencies. In such situations, interactions [9] between the variables can occur. The interaction between variables could have more impact on the state of the asset than the variables alone. Interaction features are features that were developed from the base variables in an attempt to represent a particular interaction. Typically, interactions are expected based on the domain knowledge of the base variables.
An example manufacturing process with interaction can be some component that can function properly for a long time even when overheated. Also, it can operate in above-optimal pressure without much risk of component failure.
However, when high pressure is combined with high temperature, then this interaction is likely to cause a breakdown in the near future. In other words, the product temperature * pressure could be a key feature in the precise prediction of RUL.
In Apache Spark ML, the Interaction transform [10] can be used to efficiently derive the cross-products interaction features from the basic variables:

The transformed df_with_interaction has the interaction feature appended:
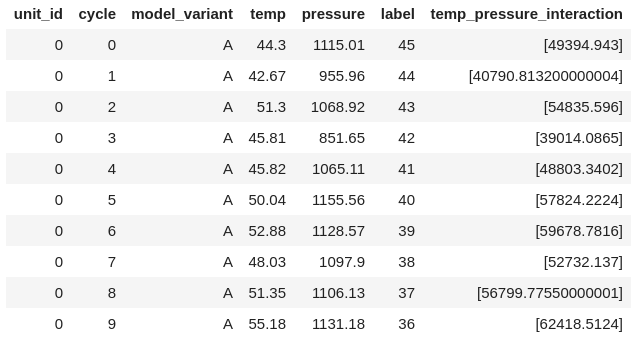
The appended column is a flattened vector and contains more elements in case one of the base variables is a Vector type column instead of Double.
Spark’s PolynomialExpansion [11] feature transform can be useful for generating a lot of interactions at once, perhaps to aid the feature development when the domain experts are unavailable or simply for features mining. On an example with 2 base features (x, y), the 2-nd degree polynomial expansion would yield a vector of interaction features (x, x * x, y, x * y, y * y).
Encoding categorical variables
In Apache Spark ML, all the features given to a learning model must be in a Vector of Double format, so encoding categorical variables is a common task. Spark’s equivalent of scikit-learn’s LabelEncoder is StringIndexer [12]. This is a standard way of encoding categorical variables. Below, you can see an example of label encoding:

Which yields encoding of model variants ‘A’ and ‘B’ into 0.0 and 1.0:

For an inverse operation of recovering original strings from the index codes, IndexToString [13] can be used. Another common way for encoding is one-hot encoding, which can be done in Spark using OneHotEncoder [14].
Time-domain features
As described in the “Temporal aspect in predictive maintenance data” section, the quality of RUL predictions can benefit greatly from time window-based aggregate features. This type of processing could be done outside the ML pipeline while preparing the initial dataset with Spark SQL. However, doing time window processing as a transformer within a pipeline allows tuning this processing to select a version that works best within the whole pipeline (e.g. tune the window size, try different aggregations and columns).
Apache Spark Machine Learning library provides the SQLTransformer [15] to formulate any SQL query and leverage Spark SQL engine for the execution of it. The only difference is that instead of the table name, __THIS__ must be used. Let’s compute mean and variance statistics of temp and pressure using a time window of 5 cycles:

Which gives a DataFrame with_time_windows:

This is only a simple example of how time-domain features could be incorporated. By developing more queries, one could add more time-window sizes (e.g. 10, 15, 30), compute different statistics (e.g. kurtosis), add “all-time” statistics computed from the first cycle, and add some raw time-related features (e.g. raw value in the previous cycle, 5 cycles ago). Adding these types of processing can be very expensive computationally, hence the distributed nature of Apache Spark ML is especially useful here.
Signals in the time domain have a representation in the frequency domain, where we can observe signal peaks at some frequencies. Vibration diagnostics is a proven way for machine condition monitoring. Degrading the health of machinery can be often observed via patterns in the frequency-domain representation of the signals coming from the sensors measurements linked to the component.
Frequency-domain-based features can be good indicators of faults such as bearing faults, imbalances, and looseness. Apache Spark ML has Discrete Cosine Transform (DCT) [16] which can be used to develop features based on frequency. DCT is similar to the discrete Fourier transform, but using only real numbers and easier to compute.
Other feature engineering
Apache Spark Machine Learning library has many other functions that facilitate feature development. There are implementations of most of the standard feature engineering operations like StandardScaler [17] for normalization (features scaling), Imputer [18] for handling missing values, and PCA [19] for dimensionality reduction.
At the end of the feature development process in Apache Spark ML, there is a special high-level transformation VectorAssembler [20] that is almost always required before passing the featured dataset to the estimator. You simply need to concatenate multi-column features into a Vector in a single column, which is a required format for features to be used with Spark models. Taking the indexed_df from the encoding example, we would need to concatenate the temp, pressure, and engine_model_idx columns:

Where the assembled_df DataFrame has features column ready to be learned from by an MLlib’s model:
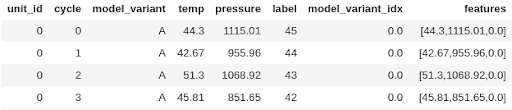
At this point, the only 2 columns that are going to be used by a learning model would be features and label columns.
Regression and classification in Apache Spark machine learning
Once the feature development is finished, a classification or regression algorithm has to be chosen and fit on the dataset. All algorithms in Apache Spark ML are Estimators that are trained on the input DataFrame and become a trained Model transformation.
Examples of classification algorithms available in Spark are Logistic regression, Random forest classifier, Gradient-boosted tree classifier, and Naive Bayes. For regression algorithms, examples include Generalized linear regression, Random forest regression, and Gradient-boosted tree regression. These are all standard Machine Learning algorithms, only implemented in a distributed, scalable version. All the listed algorithms can learn from a dataset consisting of thousands of features and any number of training examples. The main limitations are resources that the cluster manager (e.g. YARN on a Hadoop cluster) can allocate to the Apache Spark machine learning application running the algorithm.
An example of creating a Random Forest classifier:

The predictions DataFrame stores the prediction column with the classes assigned to the observations from the test set. Based on the resulting predictions, one could now compute various metrics to evaluate the quality of the model before deploying it.
Then, a likely one needs to use different learning hyperparameters, modify the feature development, or use a different learning algorithm altogether. This is a lengthy process that can be aided immensely by using pipelines and automatic model selection.
Predictive maintenance – Apache Spark ML pipeline
In the previous section, we saw that creating a learning model, training it, and generating predictions with it is fairly easy. This task is rarely done alone in a one-off fashion. Manually trying out models with different sets of hyperparameters (e.g. numTrees, maxDepth in the previous example) would be very tedious and not statistically sound. In practice, hyperparameter tuning (model selection) is done automatically with the use of a validation set, parameters grid search space, and an evaluator. Tuning can be done on the entire pipeline or separately for different estimators, but the former approach is preferred.
Two main tools for model selection in Apache Spark ML are CrossValidator (if we want to do k-fold cross-validation [21]) and TrainValidationSplit (if we want to just split the dataset into a training set and validation set). The k-fold cross-validation implemented by the CrossValidator is among the best approaches for hyperparameter tuning and is definitely more reliable than simple train-validation splitting.
Cross-validation is very expensive computationally. For example, suppose we use 10 folds on a pipeline that has 4 hyperparameters with 5 possible values each. In this case, a total of (5*5*5*5)*10=6250 different versions of the pipeline models must be trained. This is actually a modest example because in real ML cases there are likely more hyperparameters. The distributed nature of Apache Spark ML is again very useful, as different sets of parameters can be evaluated in parallel.
Below you can see an example code of a pipeline that performs feature engineering and RUL regression with Gradient Boosting Trees (GBTs), using the tiny synthetic dataset from the beginning. Note that a CrossValidator requires an Estimator (here, a pipeline), a set of ParamMaps, and an Evaluator (here, RegressionEvaluator is used with its default Root mean square error metric).


The best pipeline with the best model can be accessed via cvModel.bestModel. Its stages attribute contains each stage’s final pick. For example, the first stage contains the bucketizer and the last stage is the best GBTs model.
The next steps would include persisting the final model, deploying it and monitoring the performance statistics.
Interested in machine learning? Read our article: Machine Learning. What it is and why it is essential to business?
Additional videos
Using Apache Spark for Predicting Degrading and Failing Parts in Aviation
https://www.youtube.com/watch?v=BzHg11QmEwI
How to benefit from predictive maintenance (by Bosch)
Also check out our machine learning consulting services to learn more.
References
[1] Apache Spark, URL: https://spark.apache.org/, accessed June 7 2021.
[2] Apache Spark, Machine Learning Library (MLlib) Guide, URL: https://spark.apache.org/docs/latest/ml-guide.html, accessed June 7 2021.
[3] Wikipedia.org, Predictive maintenance, URL: https://en.wikipedia.org/wiki/Predictive_maintenance, accessed June 7 2021.
[4] Apache Spark, ML Pipelines, URL: https://spark.apache.org/docs/latest/ml-pipeline.html#transformers, accessed June 7 2021.
[5] Apache Spark, ML Pipelines, URL: https://spark.apache.org/docs/latest/ml-pipeline.html#estimators, accessed June 7 2021.
[6] Google Developers ML course, Bucketing, URL: https://developers.google.com/machine-learning/data-prep/transform/bucketing, accessed June 7 2021.
[7] Apache Spark, Extracting, transforming and selecting features, Bucketizer URL: https://spark.apache.org/docs/latest/ml-features.html#bucketizer, accessed June 7 2021.
[8] Apache Spark, Extracting, transforming and selecting features, QuantileDiscretizer URL: https://spark.apache.org/docs/latest/ml-features.html#quantilediscretizer, accessed June 7 2021.
[9] Wikipedia.org, Interaction (statistics), URL: https://en.wikipedia.org/wiki/Interaction_(statistics), accessed June 7 2021.
[10] Apache Spark, Extracting, transforming and selecting features, Interaction URL: https://spark.apache.org/docs/latest/ml-features.html#interaction, accessed June 7 2021.
[11] Apache Spark, Extracting, transforming and selecting features, PolynomialExpansion URL: https://spark.apache.org/docs/latest/ml-features.html#polynomialexpansion, accessed June 7 2021.
[12] Apache Spark, Extracting, transforming and selecting features, StringIndexer URL: https://spark.apache.org/docs/latest/ml-features.html#stringindexer, accessed June 7 2021.
[13] Apache Spark, Extracting, transforming and selecting features, IndexToString URL: https://spark.apache.org/docs/latest/ml-features.html#indextostring, accessed June 7 2021.
[14] Apache Spark, Extracting, transforming and selecting features, OneHotEncoder URL: https://spark.apache.org/docs/latest/ml-features.html#onehotencoder, accessed June 7 2021.
[15] Apache Spark, Extracting, transforming and selecting features, SQLTransformer URL: https://spark.apache.org/docs/2.2.0/ml-features.html#sqltransformer, accessed June 7 2021.
[16] Apache Spark, Extracting, transforming and selecting features, Discrete Cosine Transform (DCT) URL: https://spark.apache.org/docs/latest/ml-features.html#discrete-cosine-transform-dct, accessed June 7 2021.
[17] Apache Spark, Extracting, transforming and selecting features, StandardScaler URL: https://spark.apache.org/docs/latest/ml-features.html#standardscaler, accessed June 7 2021.
[18] Apache Spark, Extracting, transforming and selecting features, Imputer URL: https://spark.apache.org/docs/latest/ml-features.html#imputer, accessed June 7 2021.
[19] Apache Spark, Extracting, transforming and selecting features, PCA URL: https://spark.apache.org/docs/latest/ml-features.html#pca, accessed June 7 2021.
[20] Apache Spark, Extracting, transforming and selecting features, VectorAssembler URL: https://spark.apache.org/docs/latest/ml-features.html#vectorassembler, accessed June 7 2021.
[21] Wikipedia.org, Cross-validation (statistics), URL: https://en.wikipedia.org/wiki/Cross-validation_(statistics), accessed June 7 2021.
Category:





