
September 26, 2025
ContextClue Graph Builder: Technical Architecture and Implementation
Author:

CSO & Co-Founder
Reading time:
4 minutes
ContextClue Graph Builder is an open-source Python toolkit that converts unstructured documents into connected knowledge graphs. It extracts entities and relationships from PDFs, reports, and text files, then constructs queryable graph structures that preserve semantic connections between concepts.
The system transforms document collections from isolated text repositories into interconnected knowledge bases. Instead of searching for keywords across separate files, users can explore relationships between concepts, trace dependencies, and discover connections that span multiple documents.
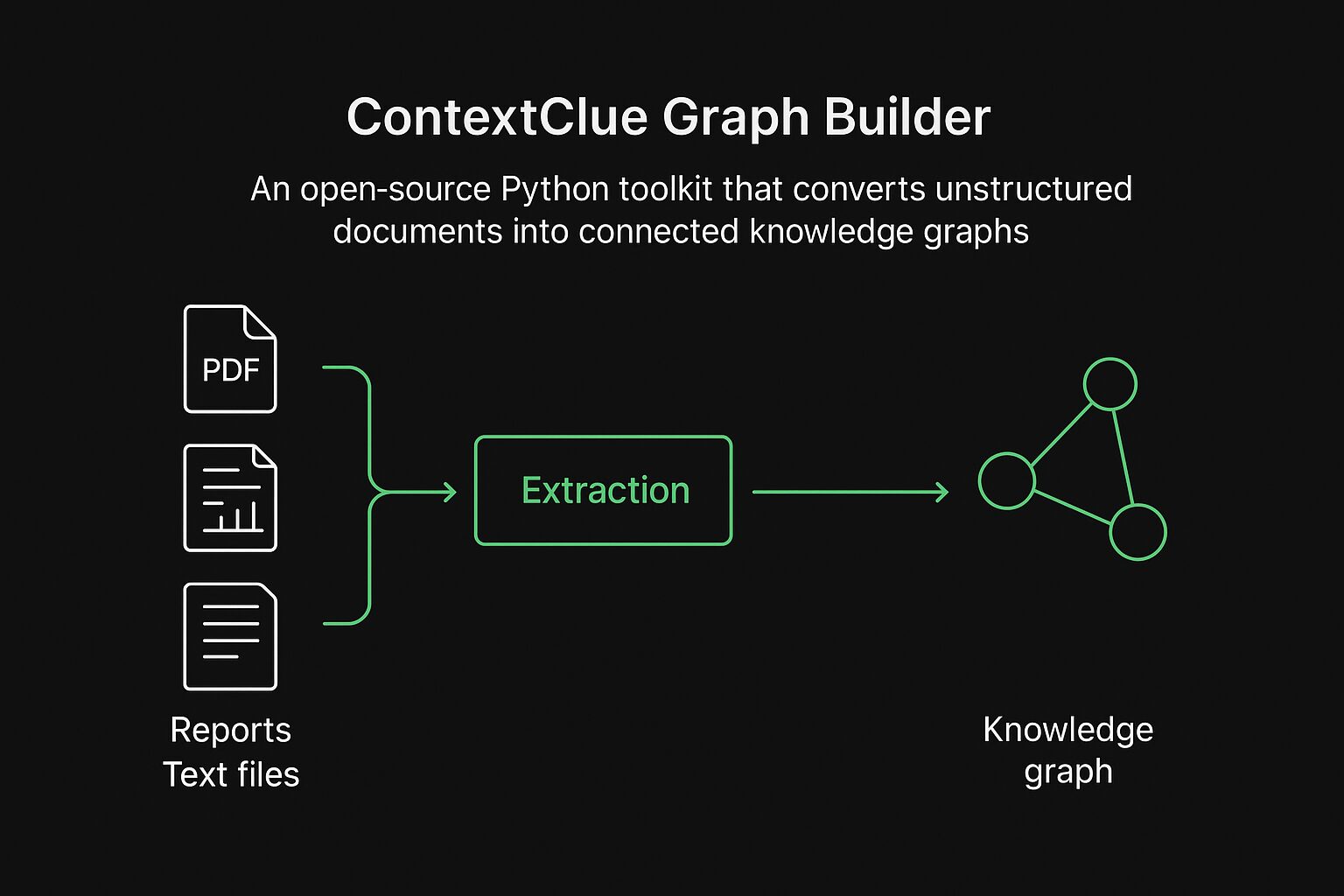
What Problem It Solves
Organizations typically store critical knowledge in static document formats that limit discoverability and relationship understanding. Technical documentation, reports, and manuals contain implicit connections that traditional search cannot surface effectively.
Knowledge graphs address this limitation by making relationships explicit. When the system processes documentation and identifies entities such as “API endpoint” or “database configuration,” it maps connections to related concepts across the entire document collection, revealing how different system components interact and depend on one another.

ContextClue Graph Builder joins ContextCheck (data quality and validation) in Addepto’s open-source toolkit collection.
Technical Architecture
Building a production-ready document-to-graph pipeline involves complex computational challenges, including layout analysis, entity resolution, relationship inference, and incremental graph updates. The difference between a prototype and a scalable system lies in architectural decisions that handle real-world complexity while maintaining performance and reliability.
Four-Layer Design
ContextClue Graph Builder employs a modular architecture with separation of concerns. This design enables independent component optimization, simplifies testing and maintenance, and provides resilience against individual component failures.
- The extraction layer processes diverse document formats, including PDFs with complex layouts, tables spanning multiple pages, and multi-column text structures. Specialized extractors operate in parallel, each optimized for specific content types and formats.
- The processing layer transforms extracted data into structured information. There is automated matching that can use multiple documents and merge sources or link entities.
- The graph construction layer maintains the knowledge graph in memory using atomic update operations. New documents integrate incrementally without requiring complete graph reconstruction, enabling continuous system operation during document processing.
Technology Stack
FastAPI-based service: for building graphs via API requests, eliminating the need to install additional tools on the client side and helping to avoid integration and dependency issues.
Business impact: Removes integration and dependency hurdles during document processing operations.
Poetry Dependency Management: Deterministic dependency resolution through lock files ensures environment consistency across development, testing, and production stages. This eliminates deployment inconsistencies and accelerates development environment setup.
Business impact: Reduces onboarding time, minimizes deployment failures, and provides predictable infrastructure costs.
Docker Containerization: Multi-stage builds create optimized production images with minimal footprint. The containerized approach enables deployment across diverse infrastructure environments, including private servers, cloud platforms, and on-premises systems.
Business impact: Eliminates vendor lock-in, ensures consistent deployments, and facilitates horizontal scaling.
Three-Stage Document Processing Workflow
- Stage 1: Document Ingestion The system receives documents through API endpoints or file system monitoring. Document type detection routes each file to appropriate extraction pipelines, with different processing strategies for technical documentation, reports, and structured data.
- Stage 2: Parallel Extraction Multiple extraction processes operate concurrently rather than sequentially. Text extraction, table detection, and entity recognition execute simultaneously, with error isolation preventing individual extractor failures from affecting other processing components.
- Stage 3: Graph Integration Newly extracted entities undergo comparison with existing graph elements. Entity resolution algorithms identify semantic equivalents (e.g., “Database Server” and “DB Server”) for consolidation. Relationship mapping connects new information to existing knowledge structures, expanding the graph incrementally.
Configuration-based Customization
Entity type modifications require only JSON configuration file updates rather than code changes. Domain-specific relationship rules integrate through configuration parameters, enabling the system to rebuild extraction logic without Python code modifications.
For advanced customization requirements, the plugin architecture supports custom extractors that integrate with core infrastructure. Plugin components inherit parallel processing capabilities, error handling mechanisms, and automatic API integration.
Implementation
The complete system is available under MIT license through GitHub.
Local deployment requires minimal setup time:
git clone <https://github.com/Addepto/graph_builder> cd graph_builder && poetry install poetry run uvicorn contextclue.api:app --reload
GitHub repository:
https://github.com/Addepto/graph_builder
Conclusion
Document processing system development involves significant computational complexity across layout analysis, entity resolution, and graph construction domains. This toolkit addresses these technical challenges through proven architectural patterns, enabling development teams to focus on application-specific features rather than foundational infrastructure.
The architectural decisions directly impact operational metrics, including processing performance, infrastructure costs, and user experience. Well-designed systems reduce development time while providing scalable, maintainable solutions for production environments.
Category:





