
April 01, 2025
Stream Data Model and Architecture: The Ultimate Guide for 2025
Author:

CEO & Co-Founder
Reading time:
15 minutes
In 2020, the total amount of data generated by every person around the world was 1.7 megabytes per second [1], totaling 44 zettabytes. By 2025, the amount of stream data generated globally is estimated to reach an outstanding 463 zettabytes [2]. This tremendous amount of data being generated has prompted many organizations to ditch batch processing and adopt real-time data streams in an effort to stay abreast with the ever-changing business needs.
Although stream data architecture technologies are not a new concept, they have certainly come a long way over the past few years. The industry is now transitioning from the painstaking integration of Hadoop frameworks toward single-service solutions capable of transforming event Streams from non-traditional data sources into analytics-ready data [3].
In this article, we’ll cover stream data architecture in its entirety, from what it is, the potential benefits it can provide to your organization and the components of streaming data architecture.
Key Takeaways
- Data streaming is the continuous flow of data that’s essential for organizations generating 463+ zettabytes globally
- Real-time data processing architectures provide critical competitive advantages through immediate insights
- Modern streaming solutions offer superior scalability, pattern detection, and ROI compared to traditional data processing
- Implementation requires careful planning to overcome integration, scalability, and data consistency challenges
- Stream data centers are evolving to meet the demands of continuous data flows and real-time analytics

What is Streaming Data Architecture?
Streaming data is data in motion – a continuous flow of data generated in real-time from various data sources.
Streaming data arrives sequentially over time in a continuous fashion rather than in bulk batches. This characteristic makes streaming data platforms essential for organizations dealing with real-time processing requirements.
A streaming data architecture is a network of specialized software components designed to:
- Ingest massive volumes of real-time data from multiple stream sources
- Process raw data as it’s generated
- Store, analyze, and transform data for immediate business insights
- Aggregate and enrich the data before it becomes stale in another data system
Unlike conventional batch data architectures, streaming solutions handle data flows continuously, enabling real-time analytics that keep organizations competitive in today’s fast-paced business environment.
Common Stream Data Sources
Examples include a sensor reporting the current temperature or a user clicking a link on a web page.
Stream data sources include:
- Server and security logs
- Data from consumers’ mobile devices
- Data firehose from IoT sensors and connected devices
- Real-time advertising platforms
- Social media feeds
- Changes in the stock market
- Financial data showing stock price movements
- Enterprise data from monitoring systems

Stream Processing vs. Batch Processing: Understanding the Difference
When working with data streams, organizations must choose between stream processing systems and traditional data processing approaches:
| Feature | Apache Kafka | Amazon Kinesis Data | Google Pub/Sub | Azure Event Hubs |
|---|---|---|---|---|
| Scalability | Horizontal scaling | Auto-scaling | Global auto-scaling | Auto-scaling |
| Integration | Broad ecosystem | AWS services | GCP services | Azure services |
| Data Consistency | Configurable | Built-in | Built-in | Built-in |
| Disaster Recovery | Manual configuration | Automatic | Automatic | Automatic |
| Cost Model | Self-managed costs | Pay-as-you-go | Pay-as-you-go | Flexible tiers |
| Data Volume | Petabytes | Terabytes | Petabytes | Terabytes |
| Ease of Implementation | Moderate complexity | Simplified management | Simplified management | Moderate complexity |
The complexity of modern business requirements has rendered traditional data processing methods increasingly obsolete.

Organizations need to act on data in motionbefore it becomes stale, making data streaming platforms essential for maintaining competitive advantage.
How to Stream Data Model and Architecture in Big Data
An effective streaming architecture must account for the distinctive characteristics of data streams, which tend to generate copious amounts of structured and semi-structured data that require ETL and pre-processing to be useful.
Due to its complexity, stream processing cannot be solved with one ETL tool or database. That’s why organizations need to adopt solutions consisting of multiple building blocks that can be combined with data pipelines within the organization’s data architecture.
Although stream processing was initially considered a niche technology, it is hard to find a modern business that does not have an e-commerce site, an online advertising strategy, an app, or products enabled by IoT.
Each of these digital assets generates real-time event data streams, thus fueling the need to implement a streaming data architecture capable of handling powerful, complex, and real-time analytics.
How Data Streaming Works
Streaming data applications follow a general workflow:
- Data Generation: Raw data is continuously generated from various stream sources
- Ingestion: A stream processor captures the continuous flow of data
- Processing: Data pipelines transform, filter, and enrich the data elements
- Analysis: Streaming analytics platforms detect patterns and generate insights
- Storage: Data lake and data warehouse systems store processed data
- Action: Applications respond to insights, often through automated processes
This workflow enables organizations to build a stream processing architecture that handles data in motion efficiently.
7 Critical Benefits of Stream Data Processing
The main benefit of stream processing is real-time insight. We live in an information age where new data is constantly being created.
Organizations that leverage streaming data analytics can use real-time information from internal and external assets to inform their decisions, drive innovation, and improve their overall strategy.
Here are a few other benefits of data stream processing:
Handle the never-ending stream of events natively
Batch processing tools need to gather batches of data and integrate the batches to gain a meaningful conclusion. By reducing the overhead delays associated with batching events, organizations can gain instant insights from huge amounts of stream data.
Real-time data analytics and insights
Stream processing processes and analyzes data in real-time to provide up-to-the-minute data analytics and insights. This is very beneficial to companies that need real-time tracking and streaming data analytics on their processes. It also comes in handy in other scenarios, such as detection of fraud and data breaches and machine performance analysis.

Simplified data scalability
Batch processing systems may be overwhelmed by growing volumes of data, necessitating the addition of other resources, or a complete redesign of the architecture. On the other hand, modern streaming data architectures are hyper-scalable, with a single stream processing architecture capable of processing gigabytes of data per second [4].
Detecting patterns in time-series data
Detection of patterns in time-series data, such as analyzing trends in website traffic statistics, requires data to be continuously collected, processed, and analyzed. This process is considerably more complex in batch processing as it divides data into batches, which may result in certain occurrences being split across different batches.
Increased ROI
The ability to collect, analyze and act on real-time data gives organizations a competitive edge in their respective marketplaces. Real-time analytics makes organizations more responsive to customer needs, market trends, and business opportunities.
Improved customer satisfaction
Organizations rely on customer feedback to gauge what they are doing right and what they can improve on. Organizations that respond to customer complaints and act on them promptly generally have a good reputation [5].
Fast responsiveness to customer complaints, for example, pays dividends when it comes to online reviews and word-of-mouth advertising, which can be a deciding factor for attracting prospective customers and converting them into actual customers.
Losses reduction
In addition to supporting customer retention, stream processing can prevent losses as well by providing warnings of impending issues such as financial downturns, data breaches, system outages, and other issues that negatively affect business outcomes. With real-time information, a business can mitigate or even prevent the impact of these events.

Read more about Data Engineering in Startups: How to Manage Data Effectively
Key Use Cases for Streaming Data Architecture
Traditional batch architectures may suffice in small-scale applications [6]. However, when it comes to streaming sources like servers, sensors, clickstream data from apps, real-time advertising, and security logs, stream data becomes a vital necessity as some of these processes may generate up to a gigabyte of data per second.
Stream processing is also becoming a vital component in many enterprise data infrastructures.
For example, organizations can use clickstream analytics to track website visitor behaviors and tailor their content accordingly.
Likewise, historical data analytics can help retailers show relevant suggestions and prevent shopping cart abandonment.
Another common use case scenario is IoT data analysis, which typically involves analyzing large streams of data from connected devices and sensors.
E-Commerce and Retail
- Real-time inventory management using stream data centers
- Dynamic pricing optimization through continuous data analysis
- Personalized recommendation engines using data structures from customer behavior
- Shopping cart abandonment prevention with real-time processing
Financial Services
- Fraud detection through analysis of data in the data stream
- Algorithmic trading based on stock price movements
- Risk assessment and compliance through continuous data evaluation
- Customer transaction monitoring through data read operations
Manufacturing and IoT
- Predictive maintenance using data from IoT streams
- Quality control monitoring through real-time data processing
- Supply chain optimization using characteristics of streaming data
- Equipment performance tracking with continuous data flows
Healthcare
- Patient monitoring systems with real-time layer and a batch layer for historical context
- Healthcare operations optimization using streaming data applications
- Medical device data analysis through event stream processing
- Treatment efficacy tracking using both real-time and historical data
Overcoming Stream Data Architecture Challenges
1. Business Integration Complexity
Challenge: Multiple business units and application teams working concurrently face difficulties as data comes from various systems.
Solution: Implement federation of events through multiple integration points to prevent system-wide disruptions and maintain data consistency.
2. Scalability Bottlenecks
Challenge: Growing data sets strain system resources, making operations like backups, index rebuilding, and storing streaming data increasingly difficult.
Solution: Test-run expected loads using historical data before implementation to identify and remediate potential bottlenecks in data storage before deployment.
3. Fault Tolerance and Data Guarantees
Challenge: Data from diverse sources in varying volumes and formats requires robust data platforms to prevent disruptions.
Solution: Implement redundant components, automatic failover mechanisms, and guaranteed delivery protocols to ensure system resilience when working with data streams.
Essential Components of a Streaming Data Architecture
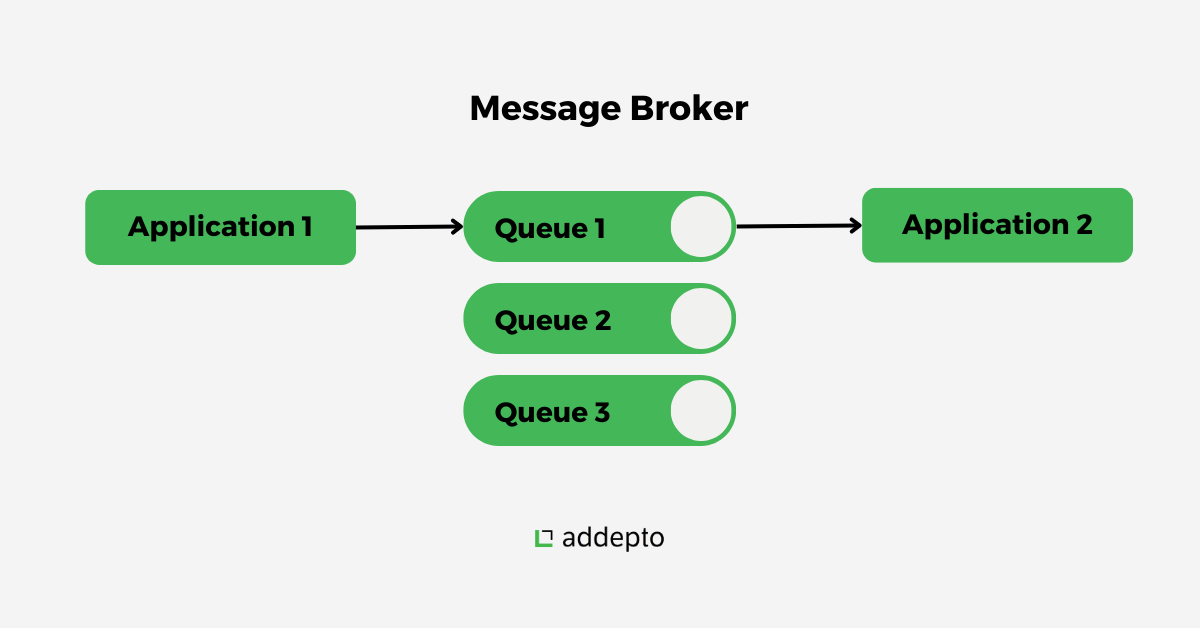
Message Broker (Stream Processor)
Functions as the central nervous system of your streaming architecture by:
- Collecting raw data from various sources (producers)
- Converting to standardized message formats
- Enabling writes of large data streams to consumers
Popular options include Apache Kafka, Amazon Kinesis Data Streams, and RabbitMQ.
 Batch and Real-Time ETL Tools
Batch and Real-Time ETL Tools
 Batch and Real-Time ETL Tools
Batch and Real-Time ETL ToolsTransform and structure data from multiple message brokers before analysis by:
- Receiving queries from data scientists
- Gathering events from message queues
- Generating results through query application
- Performing joins, aggregations, and transformations to handle data flow
Streaming Data Storage
Cloud-based data lakes provide:
- Long-term, cost-effective storage for massive event data volumes
- Flexible integration points for external tools
- Historical data persistence alongside real-time processing
- Ability to separate data from the storage layer for efficient processing
Data Analytics/Serverless Query Engine
Extract actionable value from processed data through:
- Query engines for structured analysis
- Text search engines for unstructured content
- Streaming analytics tools like Amazon Kinesis Data Analytics and Azure Stream Analytics
Advanced Streaming Architecture Patterns
Idempotent Producer
Prevents duplicate events by assigning each producer a unique ID and sequence number, ensuring data consistency without manual intervention.
Event Splitter
Divides complex events into multiple simpler events (e.g., splitting an e-commerce order into individual data elements) for more granular analysis.
Event Grouper
Aggregates logically similar events and counts occurrences over specified time periods to enable threshold-based actions on new data.
Claim-Check Pattern
Optimizes message bus performance by storing large data structures (videos, images) externally and sending only reference pointers through the messaging platform.
Comparison of Popular Streaming Data Platforms
Working with streaming data requires selecting the right platform. Here’s how the major streaming data platforms compare:
| Feature | Apache Kafka | Amazon Kinesis Data | Google Pub/Sub | Azure Event Hubs |
|---|---|---|---|---|
| Scalability | Horizontal scaling | Auto-scaling | Global auto-scaling | Auto-scaling |
| Integration | Broad ecosystem | AWS services | GCP services | Azure services |
| Data Consistency | Configurable | Built-in | Built-in | Built-in |
| Disaster Recovery | Manual configuration | Automatic | Automatic | Automatic |
| Cost Model | Self-managed costs | Pay-as-you-go | Pay-as-you-go | Flexible tiers |
| Data Volume | Petabytes | Terabytes | Petabytes | Terabytes |
| Ease of Implementation | Moderate complexity | Simplified management | Simplified management | Moderate complexity |
Implementing Your Stream Data Architecture: Best Practices
- Start with clear business objectives rather than implementing technology for its own sake
- Begin with a specific use case for process streaming data before expanding
- Implement proper monitoring to ensure performance across all data applications
- Create a data governance framework specifically for streaming data
- Plan for schema evolution as data structures will inevitably change over time
- Build with failure in mind by designing comprehensive error handling for your data platform
Conclusion: The Future of Streaming Data Architecture
As organizations continue shifting from legacy data centers to decentralized, event-driven models, streaming data platforms will become the foundation of modern enterprise data infrastructure. Those who master these technologies will gain significant competitive advantages through enhanced agility, deeper customer insights, and the ability to trust stream as an enduring partner in their data strategy.
The most successful implementations will balance technical capabilities with business objectives, ensuring that real-time processing delivers tangible value rather than simply adding complexity to the data platform.
![]()
Check out our data engineering services
![]()
FAQ: Streaming Data Model and Architecture
Is streaming analytics right for my business?
Streaming analytics provides exceptional value for businesses that need real-time decision-making capabilities, particularly in e-commerce, online advertising, IoT services, financial services, and healthcare. If your organization depends on timely insights from continuously generated data, a streaming architecture is likely essential for your data center.
What are the essential tools for data streaming?
Key tools for working with streaming data include:
Message Brokers:
- Apache Kafka
- Amazon Kinesis Data Streams
- RabbitMQ
- Google Pub/Sub
ETL Tools:
- Apache Flink
- Apache Storm
- Spark Streaming
- AWS Glue
Data Storage:
- Amazon S3
- Google BigQuery
- Apache Hadoop for data lake implementation
- Snowflake for data warehouse integration
Analytics Engines:
- Elasticsearch
- Apache Druid
- ClickHouse
- Databricks for data scientists
Will I lose historical data with streaming architecture?
No, streaming architectures are designed to preserve historical data while enabling real-time processing. With proper data lake implementation, you can maintain complete data history while still benefiting from immediate insights. Modern streaming systems include scalable data storage solutions that support both real-time and historical analysis.
What are examples of streaming data in everyday life?
Streaming data includes:
- Social media feeds
- Financial market tickers showing stock price movements
- Weather sensor readings
- Website clickstream data
- IoT device telemetry
- Geolocation data from mobile devices
- Video game analytics
- Network traffic monitoring
How is data consistency maintained in streaming systems?
Stream processing systems maintain data consistency through:
- Exactly-once processing guarantees
- Transaction logs and replay capabilities
- Checkpointing mechanisms
- Idempotent operations
- Ordered sequence of data processing
- Schema validation and enforcement
What characteristics of streaming data make it challenging to work with?
The key characteristics of streaming data that create challenges include:
- Unbounded data volume
- Variable arrival rates
- Out-of-order event sequencing
- Schema evolution over time
- Requirement for low-latency processing
- Need for fault tolerance
- Integration with existing data platforms
Comparison of Popular Streaming Platforms
Streaming platforms are crucial for handling real-time data processing, enabling businesses to make timely decisions and enhance operational efficiency. Among the leading platforms are Apache Kafka, Amazon Kinesis, Google Pub/Sub, and Azure Event Hubs. Each offers unique features tailored to different needs and environments.
Overview of Each Platform
- Apache Kafka: A widely adopted, open-source distributed streaming platform known for its scalability and real-time data processing capabilities. It is particularly popular for its ability to handle high volumes of data and its robust ecosystem.
- Amazon Kinesis: A fully managed service by AWS, designed for real-time data processing and analysis. It offers serverless scalability and integrates seamlessly with other AWS services.
- Google Pub/Sub: A fully managed messaging service that provides scalable and reliable message streaming. It is ideal for decoupling data producers from consumers and supports integration with other Google Cloud services.
- Azure Event Hubs: A fully managed real-time data ingestion service by Microsoft Azure. It offers automatic scaling, disaster recovery, and multi-protocol support, making it suitable for handling large volumes of events.
Feature Comparison
| Feature | Apache Kafka | Amazon Kinesis | Google Pub/Sub | Azure Event Hubs |
|---|---|---|---|---|
| Scalability | High | High | High | High |
| Real-time Processing | Yes | Yes | Yes | Yes |
| Integration with Other Services | Limited | Extensive | Extensive | Extensive |
| Security | Configurable | Built-in | Built-in | Built-in |
| Disaster Recovery | Yes | Yes | Yes | Yes |
| Cost Efficiency | Moderate | Pay-as-you-go | Pay-as-you-go | Flexible |
| Latency | Low | Low | Low | Low |
| Ease of Use | Moderate | High | High | Moderate |
This article is an updated version of the publication from Mar 13, 2024.
References
[1]Ibm.com. Digitization: A Climate Sinner or Savior? URL: https://www.ibm.com/blogs/nordic-msp/digitization-and-the-climate/. Accessed May 29, 2022
[2] Visualcapitalist.com. How Much Data is Generated Each Day? URL: https://www.visualcapitalist.com/how-much-data-is-generated-each-day/. Accessed May 29, 2022
[3]Google.com. Goodbye Hadoop Building a Streaming Data Processing Pipeline on Google Cloud. URL: https://bit.ly/3aLqlA3. Accessed May 29, 2022
[4] Researchgate.net. Scalable Architectures for Stream Analytics and Data Predictions Dedicated to Smart Spaces. URL: https://bit.ly/3xeog78. Accessed May 29, 2022
[5]Superoffice.com. Customer Complaints Good For Business. URL: https://www.superoffice.com/blog/customer-complaints-good-for-business/. Accessed May 29, 2022
[6] ST-Andrews.ac.uk. Web Architecture. URL: https://ifs.host.cs.st-andrews.ac.uk/Books/SE9/Web/Architecture/AppArch/BatchDP.html. Accessed May 29, 2022
[7] Events.ie.edu. Benefits, and Challenges of Streaming Data. URL: https://bit.ly/3NyDhb6. Accessed May 29, 2022
[8] Diva-portal.org. URL: https://kth.diva-portal.org/smash/get/diva2:1240814/FULLTEXT01.pdf . Accessed May 29, 2022
Category:




