
February 05, 2025
AI Image Recognition in 2025 – Tools, Techniques and Use Cases
Author:

CSO & Co-Founder
Reading time:
24 minutes
AI image recognition – part of Artificial Intelligence (AI) – is a rapidly growing trend that’s been revolutionized by generative AI technologies. By 2021, its market was expected to reach almost USD 39 billion, and with the integration of generative AI, it’s poised for even more explosive growth. Now is the perfect time to join this trend and understand what AI image recognition is, how it works, and how generative AI is enhancing its capabilities.
In this blogpost we will explain everything in detail. We’ll explore how generative models are improving training data, enabling more nuanced feature extraction, and allowing for context-aware image analysis. We’ll also discuss how these advancements in artificial intelligence and machine learning form the basis for the evolution of AI image recognition technology.

Learn more about how AI Consulting Services can boost your business!
Image Recognition: what it is and how it works
We, humans, can easily distinguish between places, objects, and people based on images, but computers have traditionally had difficulties with understanding these images. Thanks to the new image recognition technology, we now have specific software and applications that can interpret visual information.
Computer Vision and Image Recognition
As always, let’s start with the basics. From time to time, you can hear terms like “Computer Vision” and or “Image Recognition”. These terms are synonymous, but there is a slight difference between the two terms. Let us explain.
Computer Vision is a wide area in which deep learning is used to perform tasks such as image processing, image classification, object detection, object segmentation, image coloring, image reconstruction, and image synthesis. In computer vision, computers or machines are created to reach a high level of understanding from input digital images or video to automate tasks that the human visual system can perform.

Learn more: The Future of Computer Vision and Artificial Intelligence
Whereas, image recognition is a field of computer vision that interprets images to aid decision-making. Image recognition is the final stage of image processing, which is one of the most important tasks of computer vision. [1]
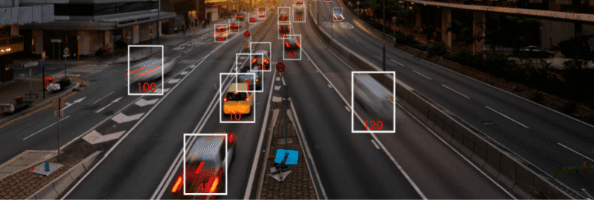
How does image recognition work?
Now, a few words about how image recognition works. Image recognition algorithms make image recognition possible. The first step here is gathering and organizing the data. Data organization means classifying each image and distinguishing its physical characteristics. Unlike humans, computers perceive a picture as a vector or raster image. So, after the constructs depicting objects and features of the image are created, the computer analyzes them.
Read our case study: Automated image quality detection engine for retail
Therefore, the correct collection and organization of data are essential for training the image recognition model because if the quality of the data is discredited at this stage, it will not be able to recognize patterns at a later stage.
The second step of the image recognition process is building a predictive model. The classification algorithm has to be trained carefully. Otherwise, it won’t be able to deliver its function. Image recognition algorithms use deep learning datasets to distinguish patterns in images. These datasets consist of hundreds of thousands of tagged images. The algorithm looks through these datasets and learns what the image of a particular object looks like. When everything is done and tested, you can enjoy the image recognition feature.

Image Recognition vs. Image Processing
You should remember that image recognition and image processing are not synonyms. Image processing is a kind of computer vision. Image processing means converting an image into a digital form and performing certain operations on it. As a result, it is possible to extract some information from such an image.
Image processing stages:
- Color image processing — the colors are processed
- Image enhancement — the quality of the image is improved, and the hidden details are extracted
- Image restoration — the image is cleaned from blurs and other unpleasant things
- Representation and description — the processes data is visualized
- Image acquisition — the image is captured and converted
- Image compression and decompression — the size and resolution of the image are changed, if necessary
- Morphological processing — the structure of the image’s objects is described
- Image recognition — specific features of the image’s objects are identified
Image Recognition vs. Image Detection
Image detection involves finding various objects within an image without necessarily categorizing or classifying them. It focuses on locating instances of objects within an image using bounding boxes.
Crucial in tasks like face detection, identifying objects in autonomous driving, robotics, and enhancing object localization in computer vision applications.
Involves algorithms that aim to distinguish one object from another within an image by drawing bounding boxes around each separate object.

Image recognition: Visual Search
The future of search will be about pictures rather than keywords.
— Pinterest CEO, Ben Silbermann
Visual search uses real images (screenshots, web images, or photos) as an incentive to search the web. Current visual search technologies use artificial intelligence (AI) to understand the content and context of these images and return a list of related results. It is applied in more and more industries. One of them is e-commerce.
For instance, Boohoo, an online retailer, developed an app with a visual search feature. A user simply snaps an item they like, uploads the picture, and the technology does the rest. Thanks to image recognition, a user sees if Boohoo offers something similar and doesn’t waste loads of time searching for a specific item.
Other applications of image recognition (already existing and potential) include creating city guides, powering self-driving cars, making augmented reality apps possible, teaching manufacturing machines to see defects, and so on. There is even an app that helps users to understand if an object in the image is a hotdog or not.
![]()
Visual Search statistics
- 90% of information transmitted to the human brain is visual.
- 62% of millennials want visual search over any other new technology.
- 45% of retailers in the UK now use visual search.
- The global visual search market is estimated to exceed USD 14,727 million by 2023, an increase of + 9% over the forecast period 2018-2023. [4]
Visual Search trends
- Brands (in particular Mastercard) completely remove text from their images in favor of a designer expression of their identity.
- Google search offers more and more visual possibilities with more images and an improved user interface. Google images increasingly follow Pinterest.
- Pinterest combines visual search with text search, which should increase its reach.
- Retailers are developing their visual search capabilities, rather than relying on search engines and social networks as intermediaries. [4].
AI Image Recognition: Analyzing the Impact and Advancements
We described how image recognition works, but you may still have a lot of questions regarding how to complete those stages. Here is an answer — do image recognition using AI. Artificial intelligence makes all the features of image recognition possible. To give you a better understanding, here are some of them:
Facial recognition
With the help of AI, a facial recognition system maps facial features from an image and then compares this information with a database to find a match. Facial recognition is used by mobile phone makers (as a way to unlock a smartphone), social networks (recognizing people on the picture you upload and tagging them), and so on. However, such systems raise a lot of privacy concerns, as sometimes the data can be collected without a user’s permission.
Apart from this, even the most advanced systems can’t guarantee 100% accuracy. What if a facial recognition system confuses a random user with a criminal? That’s not the thing someone wants to happen, but this is still possible. However, technology is constantly evolving, so one day this problem may disappear.
Facial Recognition Trends in 2021
- Application of facial recognition models at airport
Face recognition is now being used at airports to check security and increase alertness. Due to increasing demand for high-resolution 3D facial recognition, thermal facial recognition technologies and image recognition models, this strategy is being applied at major airports around the world.
- Know who your customers are
In the finance and investment area, one of the most fundamental verification processes is to know who your customers are. As a result of the pandemic, banks were unable to carry out this operation on a large scale in their offices. As a result, face recognition models are growing in popularity as a practical method for recognizing clients in this industry.
- Robotic face recognition system
In 2020, India implemented an automatic facial recognition system, which will further improve the identity verification process for the National Crime Registration Bureau. It is expected that these systems will be very popular this year. [2]

Object recognition
Object recognition systems pick out and identify objects from the uploaded images (or videos). It is possible to use two methods of deep learning to recognize objects. One is to train the model from scratch, and the other is to use an already trained deep learning model. Based on these models, many helpful applications for object recognition are created. Visual search is probably the most popular application of this technology.
For example, the application Google Lens identifies the object in the image and gives the user information about this object and search results. As we said before, this technology is especially valuable in e-commerce stores and brands. [(3]).
Text detection
Everything is obvious here — text detection is about detecting text and extracting it from an image.
Pattern recognition
Pattern recognition means finding and extracting specific patterns in a given image. Those can be textures, facial expressions, etc.

Image analysis
Do you need a summary of a specific image? Then use AI for picture and image analysis. As a result, all the objects of the image (shapes, colors, and so on) will be analyzed, and you will get insightful information about the picture.
Image Recognition in Machine Learning
Machine learning algorithms play a key role in image recognition by learning from labeled datasets to distinguish between different object categories.
Convolutional Neural Networks (CNNs) are particularly effective in image recognition tasks as they can automatically detect significant features in images without human supervision, making them well-suited for tasks like object classification and localization.
Top Models and Algorithms in Image Recognition
Models like ResNet, Inception, and VGG have further enhanced CNN architectures by introducing deeper networks with skip connections, inception modules, and increased model capacity, respectively.
Additionally, algorithms such as YOLO (You Only Look Once) and Faster R-CNN have revolutionized object detection by enabling real-time identification of multiple objects in complex scenes through efficient bounding box regression and feature extraction techniques.
These top models and algorithms continue to drive innovation in image recognition applications across various industries, showcasing the power of deep learning in analyzing visual content with unparalleled accuracy and speed.
Use Cases of Image Recognition
Mobile e-commerce
An excellent example of image recognition is the CamFind API from image Searcher Inc. This technology provides an advanced level of mobile trading. CamFind recognizes items such as watches, shoes, bags, sunglasses, etc., and returns the user’s purchase options. Potential buyers can compare products in real-time without visiting websites. Developers can use this image recognition API to create their mobile commerce applications.
ViSenze is an artificial intelligence company that solves real-world search problems through deep learning and image recognition. ViSenze products are used by online buyers, online sellers, and media owners to use product recommendations and to direct advertisements. [5]

Gaming Industry
Recognition models and computer vision technologies have also had a great impact on the gaming industry. It is known that the Microsoft Kinect video game is listed in the Guinness Book of Records as the fastest-selling consumer electronics device. The game is based on computer vision and tracks the human body in real-time. [(5])
Healthcare
Detecting brain tumors or strokes and helping people with poor eyesight are some examples of the use of image recognition in the healthcare sector. The study shows that the image recognition algorithm detects lung cancer with an accuracy of 97%.
Moreover, Medopad, in cooperation with China’s Tencent, uses computer-based video applications to detect and diagnose Parkinson’s symptoms using photos of users. The Traceless motion capture and analysis system (MMCAS) determines the frequency and intensity of joint movements and offers an accurate real-time assessment.
With the increase in the ability to recognize computer vision, surgeons can use augmented reality in real operations. It can issue warnings, recommendations, and updates depending on what the algorithm sees in the operating system.

Banking
Banks are increasingly using facial recognition to confirm the identity of the customer, who uses Internet banking. Banks also use facial recognition ” limited access control ” to control the entry and access of certain people to certain areas of the facility.
For example, the Spanish Caixabank offers customers the ability to use facial recognition technology, rather than pin codes, to withdraw cash from ATMs.
Manufacturing
For pharmaceutical companies, it is important to count the number of tablets or capsules before placing them in containers. To solve this problem, Pharma packaging systems, based in England, has developed a solution that can be used on existing production lines and even operate as a stand-alone unit. A principal feature of this solution is the use of computer vision to check for broken or partly formed tablets.
Another example is a company called Sheltoncompany Shelton which has a surface inspection system called WebsSPECTOR, which recognizes defects and stores images and related metadata. When products reach the production line, defects are classified according to their type and assigned the appropriate class.
Image recognition and models play a huge role in the automotive sector. According to one report, by 2022, the total market for machine vision could reach up to $ 14.43 billion! [(6])
For example, Komatsu Ltd, a leading manufacturer of mining and construction equipment, recently announced plans to work with Nvidia to integrate the NVIDIA cloud technology package. The main reason for this was to extend site management services, security, and performance. It is also about implementing AI based on deep learning to track people and predict the movement of equipment to avoid dangerous interactions, thus increasing so increasing safety. [6]

Methods and Techniques for Image Processing with AI
Image processing is a method of converting an image into digital form and performing certain operations on it to obtain an improved image or extract useful information from it. This is a type of signal distribution in which the input is an image, such as a video frame or photo, and the output may have an image or features associated with that image.
Let’s start with the simplest things — methods of image processing. Currently, there are only two of them: analog and digital. The analog method is used for processing hard copies of images (like printouts). Above all, the mission of the digital one is to manipulate digital images using computer algorithms.
Regarding the techniques, they exist in spades, and we have already mentioned some of them. For instance, image restoration is considered both as a stage and technique of image processing. Here are some of the other techniques:
- Pixelation — turning printed pictures into the digitized ones
- Linear filtering — processing input signals and producing the output ones which are subject to the constraint of linearity
- Edge detection — finding meaningful edges of the image’s objects
- Anisotropic diffusion — reducing the image noise without removing crucial parts of the picture
- Principal components analysis — extracting the features of the image

Tools for Image Recognition
Fortunately, you don’t have to develop everything from scratch — you can use already existing platforms and frameworks. Cloud Vision API from Google is one of the most popular of them. Features of this platform include image labeling, text detection, Google search, explicit content detection, and others. If you choose this option, you will be charged per image. However, the first 1000 images used each month are free.
The next variant is Amazon Rekognition (yes, we made no mistake, that’s Rekognition). It allows adding visual analysis features to your app, integrating face-based user verification, identifying diverse objects, detecting unsafe content, etc. You will be charged for using the platform, but you can still try it for free.
Finally, the last option to mention in our article — Azure Custom Vision Service. By using it, you can develop a new custom computer vision model and train it. Upload your own labeled images, tag them, and improve your classifier — everything is very simple. Just like with Google and Amazon, where you pay only for what you use. A free trial is available as well.
Future of Image Recognition
Due to further research and technological improvements, computer vision will have a wider range of functions in the future.
Computer vision technologies will not only make learning easier but will also be able to distinguish more images than at present. In the future, it can be used in connection with other technologies to create more powerful applications.
Computer vision will play an important role in the development of general artificial intelligence (AGI) and artificial superintelligence (ASI), giving them the ability to process information as well or even better than the human visual system. In addition, by studying the vast number of available visual media, image recognition models will be able to predict the future.

Here are some of the most interesting ways that visual data can help us predict the future:
- Ocean send erosion
NC State’s Coastal & Computational Hydraulics team developed a computer vision model called XBeach to analyze flooding and erosion during hurricanes. Computer vision helps researchers predict and reduce the future impact of severe storms on local communities and sand dunes.[7]
- Deforestation
Using computer vision trained in satellite imagery and visual data from Earth, experts can remotely control those ecosystems that are threatened by deforestation. The technology helps identify and analyze emergencies and stop illegal actions before they cause unchangeable damage.[7]
- Food production
Although modern agriculture still focuses mainly on growing a single crop on a large plot, computer vision software can help farmers manage a greater variety of crops more effectively by informing them what and when to plant. Machine learning can also learn from annotated images to more correctly predict yields and analyze the condition of plants and livestock.[7]

How Generative AI Enhances AI Image Recognition
Generative AI has revolutionized the field of image recognition, pushing the boundaries of what’s possible in visual analysis. By integrating generative capabilities with traditional computer vision techniques, AI systems have become more powerful, flexible, and accurate. Let’s explore the key ways generative AI is enhancing image recognition:
Improved Training Data Generation
One of the most significant contributions of generative AI to image recognition is its ability to create synthetic training data. This augmentation of existing datasets allows image recognition models to be exposed to a wider variety of scenarios and edge cases. By training on this expanded and diverse data, recognition systems become more robust and accurate, capable of handling a broader range of real-world situations.
Enhanced Feature Extraction
Generative models, particularly Generative Adversarial Networks (GANs), have shown remarkable ability in learning to extract more meaningful and nuanced features from images. This deep understanding of visual elements enables image recognition models to identify subtle details and patterns that might be overlooked by traditional computer vision techniques. The result is a significant improvement in overall performance across various recognition tasks.
Context-Aware Recognition
By leveraging large language models and multimodal AI approaches, generative AI systems can provide context-aware image recognition. These advanced models can understand and describe images in natural language, taking into account broader contextual information beyond just visual elements. This capability allows for more sophisticated and human-like interpretation of visual scenes.
Image Restoration and Enhancement
Generative models excel at restoring and enhancing low-quality or damaged images. This capability is crucial for improving the input quality for recognition tasks, especially in scenarios where image quality is poor or inconsistent. By refining and clarifying visual data, generative AI ensures that subsequent recognition processes have the best possible foundation to work from.
Zero-Shot and Few-Shot Learning
One of the most exciting advancements brought by generative AI is the ability to perform zero-shot and few-shot learning in image recognition. These techniques enable models to identify objects or concepts they weren’t explicitly trained on. For example, through zero-shot learning, models can generalize to new categories based on textual descriptions, greatly expanding their flexibility and applicability.
Anomaly Detection
Generative models are particularly adept at learning the distribution of normal images within a given context. This knowledge can be leveraged to more effectively detect anomalies or outliers in visual data. This capability has far-reaching applications in fields such as quality control, security monitoring, and medical imaging, where identifying unusual patterns can be critical.
Synthetic Image Generation for Testing
Finally, generative AI plays a crucial role in creating diverse sets of synthetic images for testing and validating image recognition systems. By generating a wide range of scenarios and edge cases, developers can rigorously evaluate the performance of their recognition models, ensuring they perform well across various conditions and challenges.
By integrating these generative AI capabilities, image recognition systems have made significant strides in accuracy, flexibility, and overall performance. The synergy between generative and discriminative AI models continues to drive advancements in computer vision and related fields, opening up new possibilities for visual analysis and understanding.
Recent advancements in Image Recognition
Image recognition technology is experiencing rapid evolution as we enter 2025, fundamentally reshaping how machines interpret and process visual information. Key innovations in hardware integration, artificial intelligence architectures, and practical applications are driving this transformation.
Edge computing revolution
The migration of image processing to edge devices marks a significant shift from traditional cloud-based approaches. Smartphones, drones, and IoT devices now perform complex image recognition tasks locally, eliminating latency issues and enhancing real-time capabilities. This distributed computing model not only improves response times but also addresses privacy concerns by keeping sensitive data processing on-device.
Advanced AI architectures
Vision Transformers (ViTs) have emerged as powerful alternatives to traditional Convolutional Neural Networks. These architectures leverage self-attention mechanisms to capture intricate visual patterns, achieving superior accuracy across diverse applications. The success of ViTs represents a paradigm shift in how machines understand and interpret visual information.
Optimized model deployment
The development of lightweight, efficient models has become crucial for practical applications. Through techniques like model pruning and quantization, developers are creating compact versions of sophisticated AI models that maintain high accuracy while requiring minimal computational resources. This optimization enables advanced image recognition capabilities in resource-constrained environments, from mobile devices to IoT sensors.
Convergence with Natural Language Processing (NLP)
The integration of image recognition with natural language processing represents a significant breakthrough. This multimodal approach enables AI systems to understand and describe visual content in natural language, creating more intuitive and versatile applications. Visual question-answering systems and AI-powered content description tools demonstrate the practical benefits of this convergence.
Impact of Generative AI
Generative AI technologies are revolutionizing image recognition training processes. By creating synthetic training data, these systems help address the challenge of limited real-world datasets. This capability is particularly valuable in specialized fields like medical imaging, where access to diverse training data can be restricted.
Performance breakthroughs
Recent algorithms have achieved remarkable improvements in core metrics. The latest YOLO model iterations demonstrate unprecedented accuracy in real-time object detection, while new segmentation algorithms provide pixel-perfect image analysis. These advancements enable more reliable and precise applications across industries.
The rapid pace of innovation in image recognition technology suggests continued evolution toward more sophisticated, efficient, and accessible systems. These developments are creating new possibilities across industries, from healthcare and autonomous vehicles to augmented reality and security applications.
Key takeaways
Today, computer vision has benefited enormously from deep learning technologies, excellent development tools, image recognition models, comprehensive open-source databases, and fast and inexpensive computing.
Image recognition has found wide application in various industries and enterprises, from self-driving cars and electronic commerce to industrial automation and medical imaging analysis.
Generative AI has further revolutionized this field, enhancing image recognition capabilities through synthetic data generation, advanced feature extraction using GANs, context-aware analysis with multimodal AI, image enhancement for low-quality inputs, and flexible learning approaches like zero-shot and few-shot learning.
Image Recognition – FAQ
What is image recognition?
Image recognition is a mechanism used to identify objects within an image and classify them into specific categories based on visual content.
What are the differences between image detection and image recognition?
Image Detection (Object Detection) identifies and locates objects within images, marking their boundaries or positions. It’s used in applications requiring spatial awareness, like autonomous driving or surveillance. Image Recognition classifies images or objects within them into predefined categories, focusing on identifying content without specifying object locations. It’s applied in photo tagging, content moderation, and more.
How does image recognition work with machine learning?
Image recognition with machine learning involves algorithms learning from datasets to identify objects in images and classify them into categories.
What are some common applications of image recognition?
Image recognition is widely used in various fields such as healthcare, security, e-commerce, and more for tasks like object detection, classification, and segmentation.
What role does deep learning play in image recognition?
Deep learning, particularly Convolutional Neural Networks (CNNs), has significantly enhanced image recognition tasks by automatically learning hierarchical representations from raw pixel data.
Which deep learning models have revolutionized object detection tasks?
Models like Faster R-CNN, YOLO, and SSD have significantly advanced object detection by enabling real-time identification of multiple objects in complex scenes.
How can image recognition models be fine-tuned for better performance?
Fine-tuning image recognition models involves training them on diverse datasets, selecting appropriate model architectures like CNNs, and optimizing the training process for accurate results.
What is the relation between machine learning and image recognition?
Machine learning algorithms are used in image recognition to learn from datasets and identify, label, and classify objects detected in images into different categories.
What is the relation between deep learning and image recognition?
Deep learning, particularly Convolutional Neural Networks (CNNs), has significantly enhanced image recognition tasks by automatically learning hierarchical representations from raw pixel data with high accuracy. Neural networks, such as Convolutional Neural Networks, are utilized in image recognition to process visual data and learn local patterns, textures, and high-level features for accurate object detection and classification.
What are neural networks?
Neural networks are computational models inspired by the human brain’s structure and function. They process information through layers of interconnected nodes or “neurons,” learning to recognize patterns and make decisions based on input data. Neural networks are a foundational technology in machine learning and artificial intelligence, enabling applications like image and speech recognition, natural language processing, and more.
What are Convolutional Neural Networks (CNNs)?
Convolutional Neural Networks (CNNs) are a specialized type of neural networks used primarily for processing structured grid data such as images. CNNs use a mathematical operation called convolution in at least one of their layers. They are designed to automatically and adaptively learn spatial hierarchies of features, from low-level edges and textures to high-level patterns and objects within the digital image.
What role does image recognition software play in image recognition applications?
Image recognition software facilitates the development and deployment of algorithms for tasks like object detection, classification, and segmentation in various industries.
Which software tools are commonly used for implementing image recognition solutions?
Tools like TensorFlow, Keras, and OpenCV are popular choices for developing image recognition applications due to their robust features and ease of use.

However, in case you still have any questions (for instance, about cognitive science and artificial intelligence), we are here to help you. From defining requirements to determining a project roadmap and providing the necessary machine learning technologies, we can help you with all the benefits of implementing image recognition technology in your company. As always.
Do you have any questions? Drop us a line!
The article is an updated version of the publication from February 27, 2024.
References:
[1] Logicai. Artificial Intelligence (AI) Image Recognition. URL: https://logicai.io/blog/using-artificial-intelligence-ai-image-recognition/. Accessed May 27, 2021.
[2] RSK Business Solutions. Facial Recognition Trends in 2021: What’s the Deal?. URL: https://www.rsk-bsl.com/blog/facial-recognition-trends-in-2021-what-s-the-deal/. Accessed May 27, 2021.
[3] Semrush. Visual Search Guide: Who Uses It, Benefits, and Optimization Tips. URL: https://www.semrush.com/blog/visual-search-guide-benefits-optimizatiion/. Accessed May 27, 2021.
[4] Clarkboyd. Visual Search — The Ultimate Guide: Statistics, News, Trends, and Tips. URL: https://clarkboyd.medium.com/visual-search-trends-statistics-tips-and-uses-in-everyday-life-d20084dc4b0a#edc1. Accessed May 27, 2021.
[5] Marutitech. What is the Working of Image Recognition and How it is Used?. URL: https://marutitech.com/working-image-recognition/#How_to_use_image_recognition_for_your_business. Accessed May 27, 2021.
[6] Devteam. 10 Examples of Using Machine Vision in Manufacturing. URL:https://www.devteam.space/blog/10-examples-of-using-machine-vision-in-manufacturing/ . Accessed May 27, 2021.
[7] Сloudfactory. How Computer Vision Helps Us See the Future. URL:https://blog.cloudfactory.com/how-computer-vision-helps-us-see-the-future. Accessed May 28, 2021.
Category:




