
December 01, 2025
Why Most AI Models Never Reach Production? The Matter of Data Infrastructure
Author:

CSO & Co-Founder
Reading time:
11 minutes
Six months after your data science team built a promising model, it’s still not deployed. Engineering needs “a few more weeks.” Data science insists it “works fine in the notebook.” Leadership questions the investment. Teams point fingers.
Across manufacturing, logistics, and finance, we see the same pattern: brilliant models that never escape the lab. The problem isn’t talent. It’s not the algorithms.
It’s the invisible gap between research and production—what we call the “AI deployment challenge” – that kills most AI initiatives before they deliver value.
Why AI Models Get Stuck in “Productionization Hell”
Picture this: data scientists deliver a notebook showing 94% accuracy. Engineering opens it and discovers the model expects data formats that don’t exist, features that take too long to compute, and inputs that won’t be available at prediction time. What looked 90% complete is actually 10% done. Six months of rework begins.
This is what we call the “productionization hell”, and it starts the moment models built for labs meet production systems built for business.
The Problem Isn’t Your Model. It’s the Handoff.
The issue isn’t that the models are faulty per se; it’s that they’re designed for controlled lab environments: trained on clean data, with unlimited time and no constraints. Production systems are messy, real-time, and unforgiving. When these two worlds collide at the handoff, everything breaks.
Four Main AI Handoff Fails
- Training environment ≠ Production reality
Models train on clean CSV files. Production runs on messy real-time streams with missing values and schema drift.
- Speed mismatch
Features that take 10 seconds to compute in training must run in 100 milliseconds in production. A 30-second fraud model can’t score 1-second transactions.
- Data availability gap
Training uses data available days later—purchase history, final amounts, completed interactions. Production needs predictions before any of that exists.
- Optimization disconnect
Scientists optimize for accuracy. Engineers need speed, reliability, and graceful degradation.
By the time engineering receives the notebook, it’s already misaligned with production constraints. And because the work is sequential—science first, engineering later—every new production requirement forces the team to go back and redesign earlier choices.
This “build first, deploy later” pattern creates a vicious cycle. Each team works independently with different success criteria, and both lose months trying to reconcile incompatible workflows.

Read more: Why 74% of AI Initiatives Fail
How to Deploy AI Models Successfully (Fixing the Gap)
Here’s what winning companies do differently: they never create that handoff in the first place.
Engineers and data scientists collaborate from day one. They don’t meet occasionally or coordinate through tickets. Instead, they co-own the complete pipeline from data ingestion to model predictions to monitoring.
Scientists design models knowing the exact constraints of the production environment. Engineers build platforms that accelerate model development, not just deployment. The model is architected for the real environment it’ll live in, not an idealized sandbox.
Separating Pilots from Production: Critical Integration Points
Getting AI from prototype to production requires integrated technical capabilities. Most organizations don’t have this kind of expertise in-house. They have talented data scientists, yes, but ones who’ve never built production ML systems. They have skilled engineers who’ve never deployed models at scale. They have an infrastructure gap. So, let’s break it down.
1. Real-Time Data Infrastructure
Most AI models train on historical data in CSV files. But many business decisions happen in milliseconds, not hours.
Engineers build event streaming platforms that process thousands of events per second, CDC pipelines that sync databases in real-time, and serving systems that respond in under 100 milliseconds.
Data scientists design models that work with real-time constraints; choosing features available at prediction time and optimizing for speed requirements.
Together they create fraud detection that scores transactions as they happen, not in overnight batch runs.
Why it matters?
A fraud model that takes 30 seconds is worthless: the payment already processed. Batch predictions solve yesterday’s problems, real-time infrastructure lets you act when it counts.
2. Data Quality Frameworks
In training, data scientists work with clean, validated datasets. In production, data arrives messy, incomplete, and occasionally corrupted.
Engineers implement automated validation that checks incoming data before it reaches models, circuit breakers that stop bad data from flowing through, and anomaly detection that spots when distributions shift or unexpected values appear.
Data scientists define what “good” looks like from the model’s perspective: expected value ranges, normal distributions, and statistical patterns that trigger alerts when violated.
Together they create data contracts that protect model performance automatically.
Why it matters?
One corrupted source can silently tank performance. We’ve seen a vendor change their API format without notice, dropping a credit risk model from 89% to 64% accuracy. It took three weeks to discover, during which hundreds of flawed lending decisions were made. Quality frameworks catch these issues in minutes instead of weeks.
3. Feature Engineering Platforms
Features – the variables models actually use – often get rebuilt from scratch for every project. Teams calculate “customer lifetime value” five different ways across five models.
Engineers build feature stores (platforms like Feast or Tecton) that serve as central repositories, ensuring features compute identically whether you’re training on historical data or serving real-time predictions.
Data scientists design reusable features as organizational assets: well-documented, tested definitions that other teams can leverage instead of rebuilding from scratch.
Together they create shared feature libraries that cut development time by 70%.
Why it matters?
Without feature platforms, new projects waste most of their time recreating work that already exists.
4. ML-Ready Data Architecture
Traditional data warehouses are built for business intelligence (dashboards, reports, SQL aggregations, etc.) Machine learning needs something fundamentally different.
Engineers design modern lakehouse architectures (Delta Lake, Iceberg) optimized for ML workloads; fast full-table scans for training, efficient feature computation, and built-in versioning for reproducibility.
Data scientists get self-service access within governance boundaries, the ability to experiment without impacting production, and fast iteration where training takes minutes instead of hours.
Together they enable parallel experiments, faster training, and higher development velocity.
Why it matters?
Your data architecture determines innovation speed. If scientists wait weeks for access and hours for queries, they spend time on bureaucracy instead of building value.
5. Observability & Lineage
When model performance drops, you need to know why immediately. “Accuracy dropped 15%” is useless without context.
Engineers track complete data lineage: where every piece of data came from, how it was transformed, when it was last updated, showing the health of pipelines and system dependencies.
Data scientists monitor model performance metrics with data context: what data was the model using when performance changed.
Together they enable root cause debugging in minutes instead of days.
Why it matters?
Without lineage connecting performance to data changes, teams waste enormous time investigating.
Integration Maturity Curve: Where Does Your Organization Stand?
Understanding these AI integration points is one thing. Actually implementing them is another. Most companies move through predictable stages.
The Five Levels of AI Maturity
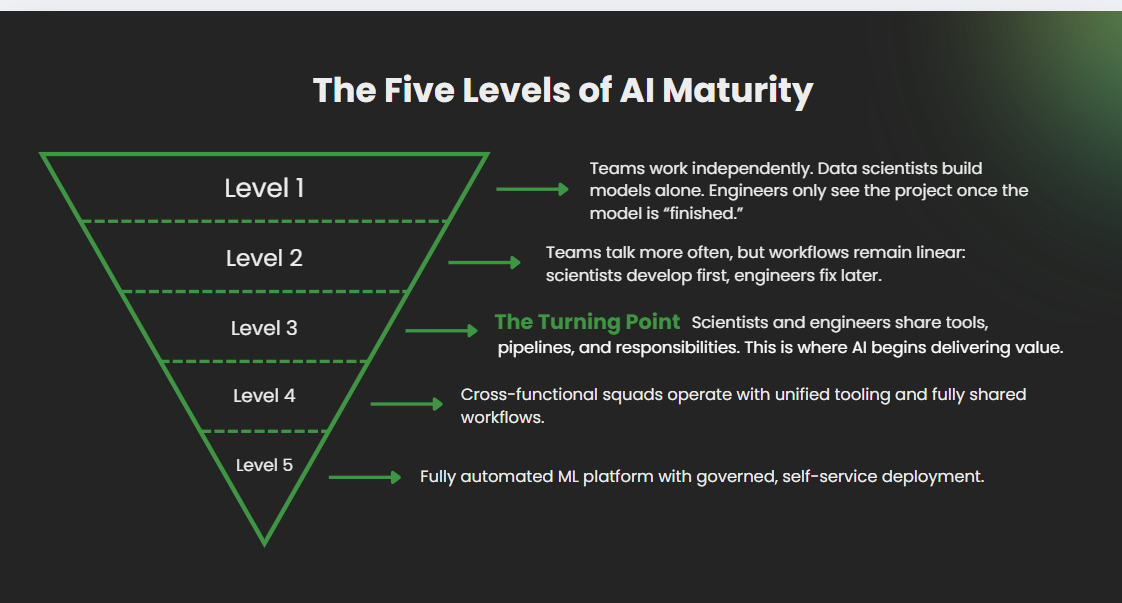
The gap between Level 2 and Level 3 is where most AI initiatives die.
Companies assume better communication will bridge it. It won’t. What’s needed is integrated infrastructure—shared platforms, joint ownership, and reusable components. This requires specialized expertise in:
- Feature stores
- ML observability
- Real-time data pipelines
- Model lifecycle automation
- Production ML engineering
Building this internally takes 18-24 months and $1.5-2.5M. That’s why many organizations choose to partner instead.
Want to identify your specific gaps and map the fastest path to Level 3?
Schedule a 30-minute AI readiness assessment. We’ll evaluate your capabilities and show you exactly what’s missing.
The Five Levels of AI Maturity: Detailed Breakdown
| Level | Team Structure | Success Rate | Timeline | Business Impact | Key Indicators |
| Level 1: Siloed Teams | Data scientists work in isolation and hand completed models to engineers | 0-10% reach production | 12-24+ months per model (or never) | Burning budget with minimal ROI |
|
| Level 2: Coordinated Communication | Regular cross-team meetings, but sequential workflows | 20-30% reach production | 6-12 months per model | Can deploy AI but it’s expensive and doesn’t scale |
|
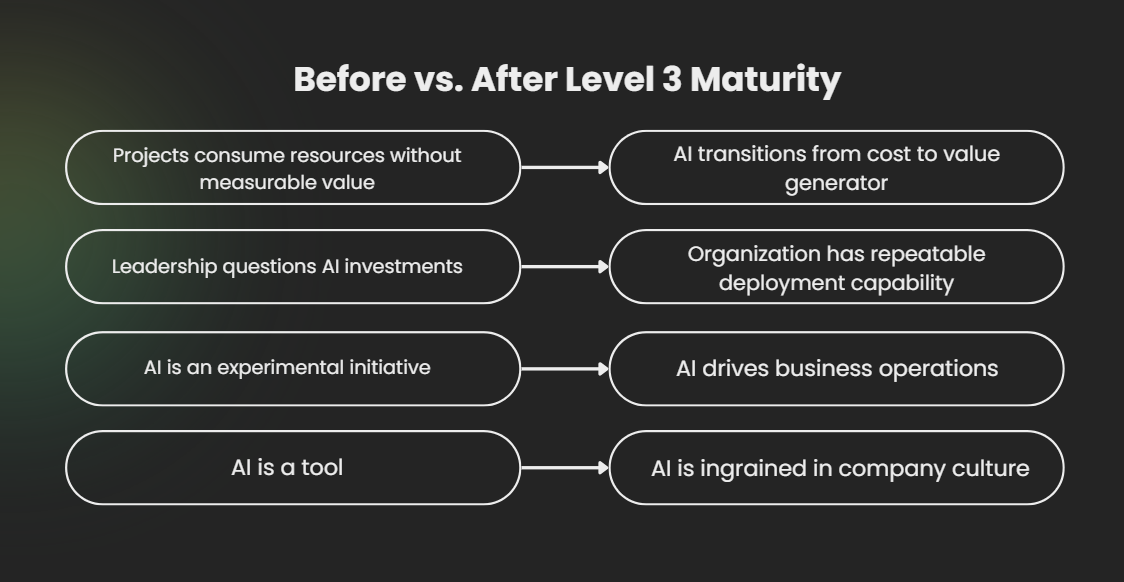
| Level 3: Integrated Infrastructure | Shared platforms, joint ownership of ML pipelines | 60-70% reach production | 3-6 months per model | AI transitions from cost to value generator—you’re getting ROI |
|
| Level 4: Collaborative Practice | Cross-functional squads with unified tooling and feature stores | 80-90% reach production | Weeks per model | AI becomes competitive advantage (shipping faster than competitors) |
|
| Level 5: Seamless Self-Service | Self-service ML platform with full automation | ~100% approved models deploy | Days per model | AI-native operations: models embedded across business |
|
AI Maturity Self-Assessment (15 Questions)
Count your “yes” answers across these 15 questions:
Real-Time Infrastructure:
- Systems provide ML features in under 100 milliseconds
- Streaming data pipelines (not just batch)
- Infrastructure handles prediction volumes at business scale
Data Quality:
- Automated validation catches bad data before it reaches models
- Can trace bad predictions to specific data issues
- Models fail safely when data doesn’t meet expectations
Feature Engineering:
- Features are reusable across models
- Central feature registry exists
- Same features work for training and inference
ML-Ready Architecture:
- Data platform optimized for ML (not just reporting)
- Scientists experiment without impacting production
- Dataset versioning and reproducible training
Observability:
- Can correlate model performance with data changes
- End-to-end lineage from prediction to source
- Root cause identification in minutes (not days)
Interpreting Your AI Maturity Score
0–5: Level 1 (Siloed)
You need foundational ML infrastructure. Models won’t reach production reliably until basic pipelines, monitoring, and feature systems are in place.
6–10: Level 2 (Coordinated)
You have some components, but no real integration. More meetings won’t fix this, you need shared tooling and joint ownership across teams.
11–15: Level 3 (Integrated)
You’ve crossed the critical threshold. Focus now on scaling, standardizing, and turning repeatable success into competitive advantage.
16+: Level 4–5 (Collaborative/Seamless)
You’re ahead of most organizations. Your challenge now is optimizing for speed, automation, and cross-team innovation.
What’s Your Next Move?
Scored 0-10? You’re in the majority, but your AI investments aren’t generating returns. The question now is whether you should try to build your own infrastructure or partner to accelerate. ask yourself three questions:
- What’s the cost of remaining at Level 1 or 2 for another 18 months?
- What market share are you losing to competitors who integrated faster?
- What’s the opportunity cost of having data scientists build infrastructure instead of domain-specific models?
There are two paths forward:
- Build it: 18-24 months, hire ML platform engineers, learn through trial and error. Choose this if AI infrastructure is core to your competitive strategy.
- Partner: 3-6 months, leverage proven patterns, focus internal teams on domain expertise. Choose this if speed matters and your differentiation is in application, not platform.
Read more: How to Choose the Right AI Company To Work With?
The Bottom Line: How to Move from AI Pilots to Production Systems
Most AI initiatives fail at integration, not innovation. You have smart people and promising models. What you don’t have is the infrastructure that turns research into production systems.
The pattern repeats everywhere: talented people working separately, models that shine on static data, engineers inheriting chaos, 6-18 month delays, and leadership losing confidence.
The organizations that break this pattern don’t just communicate better. They architect differently.
They build shared platforms from day one, give scientists and engineers joint ownership of pipelines, and treat integration as a design principle, not an afterthought.
The decision you’re facing isn’t really about AI. It’s about speed to value.
Getting there requires capabilities most companies are still developing: production ML engineering, feature infrastructure, real-time pipelines, and end-to-end observability.
How you acquire those capabilities—internally or through a partner—matters less than acknowledging that you need them.
Meanwhile, your competitors are already choosing. Some are on their fifth deployed model. Others are still burning budget on pilots that never ship.
Which one will you be?
Want to assess where your organization stands and what it would take to reach production AI? Schedule a 30-minute AI Readiness Assessment with our team. We’ll review your current capabilities, identify your specific integration gaps, and map out the fastest path from where you are to deployed AI generating business value.
Category:




