
April 14, 2020
Machine Learning Models
Author:

CSO & Co-Founder
Reading time:
9 minutes
As you may recall, we wrote about Machine Learning Techniques and Methods at the beginning of 2020. However, we think it’s vital to get back to this topic once again, as it’s much more extensive than you’d think. Today, we would like to tackle primarily these elements of machine learning models, that were not mentioned in the previous text. Here we go!
Maybe a short introduction first. Last time, we told you that machine learning models/techniques could be divided into two major categories:
- Supervised learning
- Unsupervised learning
Each category uses different techniques and is used for different purposes. Each one category has its pros and cons, and, as a rule, they aren’t interchangeable. As a result, if you’re dealing with machine learning, you have to master both these machine learning models and understand how they are applied to solve various problems.
In this article, we are going to examine especially some of the previously omitted elements of the machine learning models and focus on the pros and cons of each ML model. Let’s talk about supervised learning first.
You may also find it interesting – Machine Learning in Applications.
The supervised Machine Learning model
We want to focus primarily on four supervised machine learning models:
- Decision trees
- Random forests
- Logistic regressions
- Support Vector Machine
Interested in machine learning? Read our article: Machine Learning. What it is and why it is essential to business?
The decision trees
They are very popular, even outside the AI industry. In general, in this technique, data is continuously split according to a specific parameter (usually YES/NO). Let’s use the simplest example. The question you want to ask is ‘Should I buy a new car?’. To come to an answer, you need more data, ergo, more questions asked. Your questions could be, for instance:
 Source: blog.mindmanager.com
Source: blog.mindmanager.com
- Can I afford to buy a car/take the credit?
- Do I need a car?
- Do I have any other vehicle?
Each time you answer one of these sub-questions, you obtain more data, which allows you to make a more informed decision. And this is exactly what the decision trees are all about. They are used in operations research, strategic planning, and, naturally, machine learning. The decision tree can be explained by two entities, namely nodes and leaves. The leaves are the decisions or outcomes. And the decision nodes are where the data splits. Again, let’s use our example:
Leave: Do I need a car?
Node: YES/NO
Generally speaking, the more nodes and more leaves you have, your answer should be more accurate. But many experts believe that the decision trees fall short when it comes to obtaining as precise outcomes as possible. That’s why there is also the random forests technique.
The random forests
This supervised learning technique has a lot in common with the decision trees, hence its name. The random forests technique entails creating multiple decision trees using bootstrapped datasets of the original data and randomly selecting a subset of variables at each step of the decision tree.
 Source: tibco.com
Source: tibco.com
To simplify that a little we should say that the random forests operate by constructing a multitude of decision trees and outputting the class of the individual trees[1]. The idea is that relying on a “majority wins” model. This technique improves the decision tree, as you can minimize the risk of error that would come from just one tree.
Logistic regression
Last time, we talked about linear regression. Logistic regression is a machine learning technique that is used for classification problems based on the concept of probability. Actually, the logistic regression technique is quite similar to linear regression, but the logistic regression technique is used to model the likelihood of a finite number of outcomes, usually two (0/1). The logistic regression model is often used over linear regression, particularly when it comes to modeling probabilities of outcomes. Generally speaking, this supervised learning model is created in such a way, so that the output can only be between 0 and 1.
The support vector machine (SVM) techniques
Support Vector Machine is a supervised learning classification technique. It’s used mainly to solve the two-group classification problems. If you train your SVM model with sets of labeled training data for each category (of the two), this model is able to categorize new elements into one of these categories.
Again, let’s use a simple example: You want to categorize two sets of items: green squares and orange triangles. And your data has two features: x and y coordinates. The SVM model is sort of a classifier that, when given a pair of x, y coordinates, gives you information, if it’s either a green square or an orange triangle.
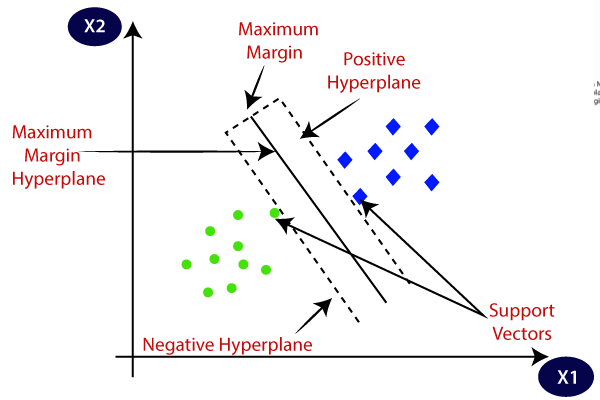 Source: javatpoint.com
Source: javatpoint.com
While we still are at the supervised machine learning models, it is crucial to mention the neural network or deep learning. It’s a complex, multi-layered model that was devised to work similarly to the human brain (hence its name). The objective of neural networks and deep learning is to capture non-linear patterns in data by adding layers of parameters to the model. As the neurons in the human brain, the deep learning algorithms use neural networks to find associations between a set of inputs and outputs. Currently, we already know that deep learning is, for instance, a perfect tool for face recognition and image analysis.
Advantages and disadvantages of the supervised machine learning model
Let’s talk about benefits first. In general, the supervised machine learning models allow you to analyze data or produce a data output from and based on the previous experience. The same way it helps to optimize the performance criteria, and solve various types of real-world computation problems. But the most important advantages of this model are the clarity of data (you work on data which is labeled and therefore easy to categorize) and ease of training.
As you already know, supervised and unsupervised machine learning models alike are for different purposes. As a result, when it comes to supervised techniques, you can’t expect the ability to learn themselves. And, for many, this is the first and major disadvantage. Are there any others?
Yes, you need to select a lot of good examples for each class while you are training the classifier before it becomes fully operational. And irrelevant input could give you inaccurate results, but it’s not necessarily a disadvantage, rather a characteristic of this model.
Now, we can switch to the unsupervised machine learning techniques.
The unsupervised machine learning model
This time, we want to show you two major unsupervised learning techniques, and these are anomaly detection and expectation–maximization.
Anomaly detection
As its name indicates, anomaly detection is all about the identification of rare items, events or observations in data–in a word, anomalies. Anomalies are also referred to as outliers, novelties, noise, deviations, and exceptions[2]. How can these anomalies be spotted? The most efficient, and simultaneously the easiest way is to track elements that differ significantly from the majority of the data. Such differences can raise suspicions. Obviously, you don’t want them in your dataset. Why? Because usually, they cause some kind of problem in the real-world, to name just bank frauds, structural defects, medical problems, or errors in a text. The anomaly detection algorithm can help you spot these anomalies and eliminate them as quickly as possible.
Expectation-maximization
It’s an iterative method used to find maximum likelihood or maximum a posteriori estimates of parameters in statistical machine learning models, primarily where the model depends on unobserved latent variables[3]. In other words, the EM algorithm provides an iterative solution to maximum likelihood estimation with latent variables. This algorithm is made up of two modes:
E-step: It’s the first mode, and it attempts to estimate the missing or latent variables.
M-step: It’s the second mode, and it attempts to optimize the parameters of the best model to explain the data (hence–maximization).
Now, where does this algorithm finds its applications? Actually, its usage is extensive, for instance, in computer vision, natural language processing, quantitative genetics, psychometrics, or medical imaging.
Advantages and disadvantages of the unsupervised machine learning model
Again, let’s start with the advantages. When it comes to unsupervised learning, there are many quite significant pros! First of all, the unsupervised machine learning model finds all kinds of unknown patterns in data[4]. Therefore, it can help you spot features that can be useful in data categorization. Moreover, in the unsupervised learning model, there is no need to label the data inputs. And unlabelled data is, generally, easier to obtain, as it can be taken directly from the computer, with no additional human intervention. This makes unsupervised learning a less complex model compared to supervised learning techniques.
However, there are also the downsides of unsupervised learning. Above all, you cannot get precise information regarding data sorting. As you know, the input data is not labeled by human specialists in advance, so the result is lower accuracy. Last but not least, the results of the unsupervised learning cannot be determined. Generally speaking, that’s because there is no prior knowledge in the unsupervised ML model, and the numbers of classes are also not known.
This was a fascinating addition to our previous article about machine learning models and techniques! Combined, these two articles constitute a great source of knowledge about machine learning!
As always, we encourage you to get in touch with us whenever you need help with implementing AI and machine learning services into your business. Our experts are always willing to answer all of your questions and show you the possibilities that AI opens for your business. See you soon!
See our machine learning consulting services to find out more.
References
[1] Wikipedia. Random forest. URL: https://en.wikipedia.org/wiki/Random_forest. Accessed Apr 14, 2020.
[2] Wikipedia. Anomaly detection. URL: https://en.wikipedia.org/wiki/Anomaly_detection. Accessed Apr 14, 2020.
[3] Wikipedia. Expectation–maximization algorithm. URL: https://en.wikipedia.org/wiki/Expectation%E2%80%93maximization_algorithm. Accessed Apr 14, 2020.
[4] Guru99. Unsupervised Machine Learning: What is, Algorithms, Example. URL: https://www.guru99.com/unsupervised-machine-learning.html. Accessed Apr 14, 2020.
Category:





