
January 28, 2022
MapReduce vs. Spark: Big data frameworks comparison

Hadoop MapReduce and Apache Spark are two of the most renowned big data architectures. Both offer a reliable network for open source technologies used to process big data and incorporate machine learning applications on them. In this article, we will take a closer look at both of them and see how they can be used.
Hadoop MapReduce was undoubtedly the ‘king’ of big data for many years until the release of Apache Spark machine learning solutions. Today, Apache Spark seems to have claimed the coveted thrown of the best big data processing framework. With Apache Spark’s better batch processing speed, myriad major organizations[1], including eBay, Alibaba, Netflix, Pinterest, and Yelp have already adopted its use in their technology stacks.
In this article, we compare MapReduce vs. Spark and see the areas in which each is strong.
Hadoop MapReduce
Apache Hadoop MapReduce was invented by software engineers Mike Cafarella and Doug Cutting[2]. The framework allows users to process large sets of data across separate computers using basic programming models.
Here are the primary components/technologies of Hadoop MapReduce:
- HDFS: HDFS is the acronym for Hadoop Distributed File System. It is responsible for distributing, storing, and retrieving information across different servers for effective parallel processing. It can process both unstructured and structured data, meaning it’s an ideal option for creating a data lake.
- MapReduce: This is the built-in data processing engine of the Hadoop MapReduce framework. It processes unstructured and structured information in a parallel and shared setting via two sequential tasks: map and reduce. Map filters and classifies data while reducing splits big data into smaller chunks.
- Yet Another Resource Negotiator (YARN): It acts as the Hadoop MapReduce’s cluster scheduler, tasked with implementing distributed workloads. It plans tasks and distributes compute resources like memory and CPU to applications. Originally, these tasks were done by MapReduce until YARN was incorporated as part of the Hadoop framework.
It might be also interesting for you: Difference Between Redshift and Snowflake
Apache Spark
Apache Spark has its origins from the University of California Berkeley[3]. Unlike the Hadoop MapReduce framework, which relies on HDFS to store and access data, Apache Spark works in memory. It can also process huge volumes of data a lot faster than MapReduce by breaking up workloads on separate nodes.
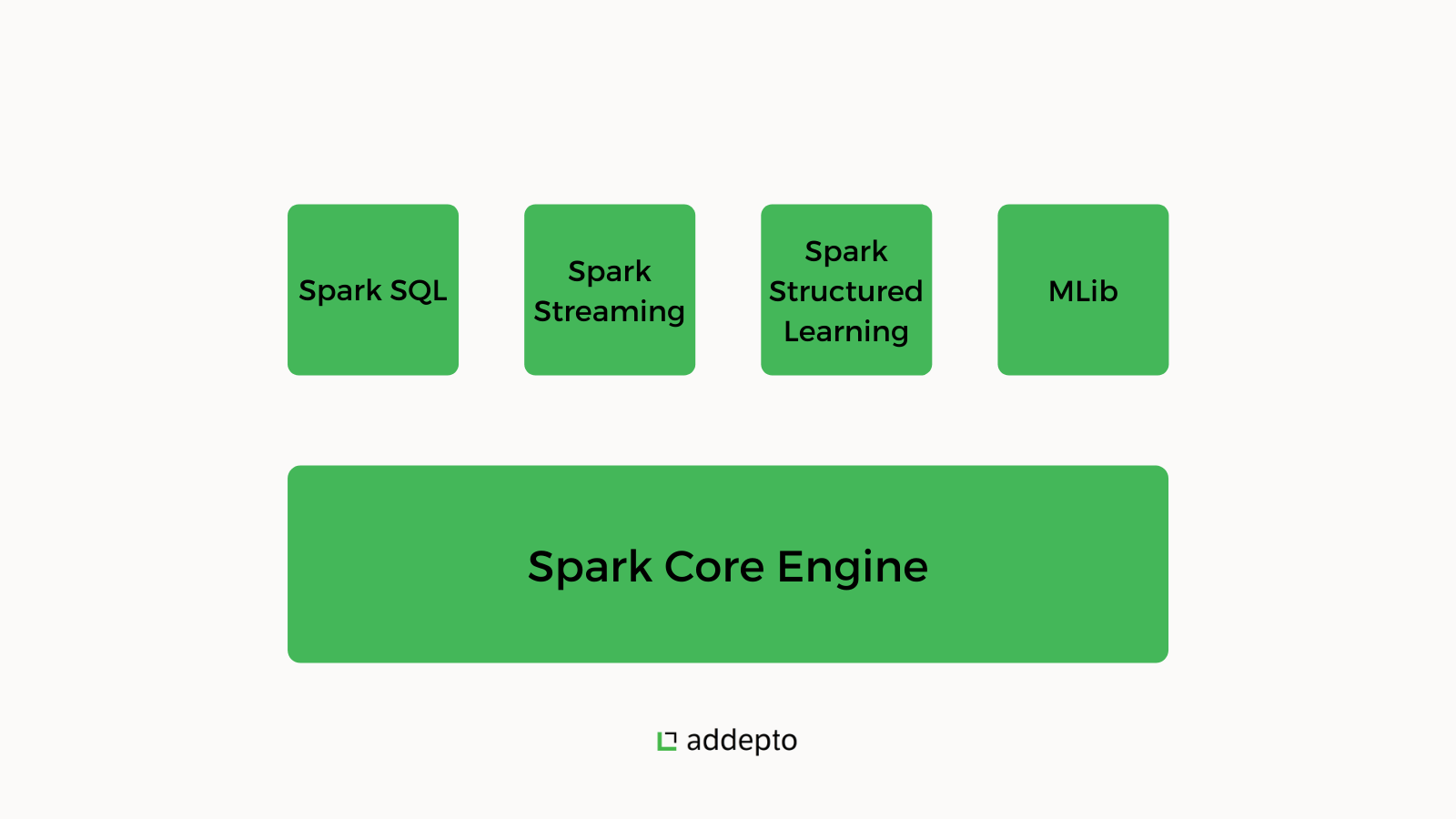
Here are the main components of Apache Spark:
- Spark Core: A built-in execution engine that manages RDD abstraction and job scheduling
- Spark SQL: Users can directly run SQL queries through Spark’s SQL component.
- Spark Streaming & Structured Streaming: Spark Streaming module collects data from separate streaming sources like Kinesis and HDFS, and splits it into micro-batches to form a continuous stream. Structured streaming, on the other hand, is a novel approach meant to minimize latency and make programming simpler.
- MLlib: MLlib is an integrated machine learning library. It includes a collection of machine learning algorithms and apparatus used for feature selection and creating machine learning conduits in-memory.
In the interest of the MapReduce vs. Spark debate, let’s look at the performance attributes of Hadoop MapReduce and Apache Spark in relation to key business areas.
Performance
Hadoop MapReduce splits data processing into 2 phases: Map stage and Reduce stage. It then writes the information back to the disk storage. Apache Spark processes jobs in Random Access Memory (RAM). As such, Apache Spark outperforms Hadoop MapReduce in terms of data processing speed. In fact, Apache Spark may run a hundred times quicker in RAM and ten times faster on-disk storage for an equivalent batch job in Hadoop MapReduce.
However, Apache Spark requires plenty of memory. This is because it normally stores its processes into memory until further notice. Running several Apache Spark applications simultaneously may bring about memory problems and hinder the performance of all the applications.
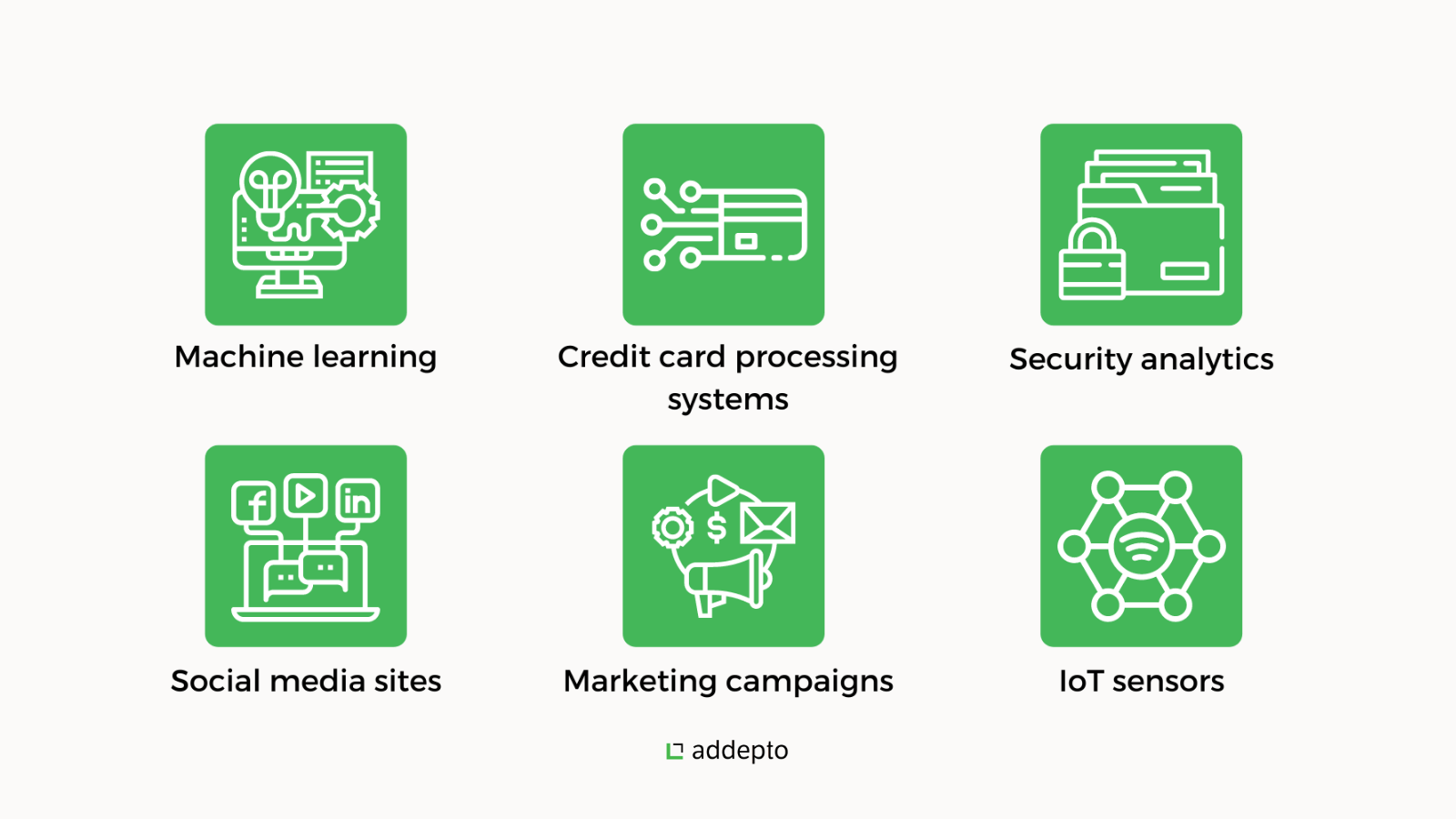
Ideally, Apache Spark is suitable for iterative tasks that need to share the same data numerous times like in:
- Credit card processing systems
- Social media sites
- Log monitoring
- IoT sensors
- Machine learning
- Security analytics
- Marketing campaigns
In contrast, Hadoop MapReduce destroys its processes once a task is done. Thus, Hadoop MapReduce is suitable for handling several longer-running applications simultaneously like:
- Predictive modeling
- Cyber threat intelligence
- Customer analytics
- Risk management
- Business forecasting
User-friendliness
Apache Spark boasts integrated, user-friendly APIs for you to write the application in Scala, Java, Python, Spark SQL, or any programming language. It also features an interactive mode that simplifies programming and provides immediate feedback on queries.
Hadoop MapReduce is written in the Java programming language. Thus, it’s notoriously hard to program and call for abstractions. Hadoop MapReduce also does not have an interactive mode. As such, users would need add-on tools like Apache Pig that need a bit of time and focus on understanding the syntax.
The bottom line in the MapReduce vs. Spark debate is that the latter is easier to program.
Data Processing Capabilities
Apache Spark accelerates the processing of large data sets, thanks to its in-memory. Users can see the same data as graphs and can even change and join the graphs using RDDs. Besides batch processing and graph processing, Apache Spark adopts the stream processing approach to perform real-time predictive analytics. Therefore, Apache Spark acts as a one-stop-shop platform for users instead of dividing tasks across separate platforms, unlike Hadoop MapReduce.
Hadoop MapReduce is ideal for batch processing. However, it doesn’t provide the option of real-time processing or graph processing, meaning you’ll have to use other platforms like Apache Storm[4], and Apache Giraph[5].
Thanks to its real-time data processing feature, Apache Spark is the go-to option for big data analytics, while Hadoop MapReduce is scalable and more efficient in batch processing.
Security
When you take into account the security comparison between MapReduce vs. Spark, Hadoop MapReduce enjoys an advanced level of security compared to Apache Spark. This is because HDFS on MapReduce accommodates access control lists and a conventional file permissions system. Hadoop MapReduce also offers Service Level Authorization when it comes to user control.
While Apache Spark’s security features are advancing, they are still no match to the high-tech security features and projects integrated with Hadoop MapReduce.
Fault Tolerance
Both Apache Spark and Hadoop MapReduce have retries and speculative implementation for every task. However, Hadoop MapReduce enjoys a small advantage here due to its reliance on disk storage instead of RAM.
If a process under Hadoop MapReduce crashes during execution, it can resume where it stalled. In contrast, Apache Spark will need to begin processing from the start. And therefore, when we talk about MapReduce vs. spark in terms of fault lenience, Hadoop MapReduce slightly edges Apache Spark.
Compatibility
Apache Spark can run as a separate application in the cloud or on top of Hadoop Cluster Scheduler. Essentially, Apache Spark integrates with similar data sources and data types that Hadoop MapReduce supports. Additionally, Apache Spark supports business intelligence tools through ODBC[6] and JDBC[7]. So both Hadoop MapReduce and Apache Spark share similar compatibility with different file formats and data sources.
Scalability
This system can scale to support large volumes of data that require sporadic access because the data can be processed and stored more affordably in disk drives than RAM. On the other hand, Apache Spark features tools that enable users to scale cluster nodes up and down based on workload needs.
Cost
Your business requirements determine your total costs when you compare MapReduce vs. Spark. In order to process huge chunks of data, Hadoop MapReduce is certainly a cost-effective option because hard disk drives are less expensive compared to memory space. Apache Spark is a more affordable option if you need real-time data processing because of its in-memory processing.
Final Thoughts: Hadoop MapReduce vs. Apache Spark
A comparison of MapReduce vs. Spark reveals the unique strengths of each of these two big data frameworks. While you may lean towards Apache Spark as the overall winner in the debate between MapReduce vs. Spark, chances are you may not use it independently. This means Apache Spark and Hadoop MapReduce aren’t mutually exclusive.
For this reason, businesses can make the most out of their synergy in various ways. Apache Spark’s impressive speed, ease of use, and excellent data processing abilities can complement Hadoop MapReduce’s security, scalability, and affordability.
Also, Apache Spark and Hadoop MapReduce can be used simultaneously for various workloads like data preparation, data engineering, and machine learning. More importantly, Hadoop MapReduce and Apache Spark can combine batch processing and real-time processing capabilities.
References
If you want to find out more about both these tools or implement big data in your company, take a look at our big data consulting services and feel free to contact us.
[1] Projectpro.io. Top 5 Apache Spark Use Cases. URL: https://www.projectpro.io/article/top-5-apache-spark-use-cases/271. Accessed January 26, 2022.
[2] Geeks forGeeks.org. Hadoop History or Evolution. URL: https://www.geeksforgeeks.org/hadoop-history-or-evolution/, Accessed January 26, 2022.
[3] Apache.org. History. URL: https://spark.apache.org/history.html, Accessed January 26, 2022.
[4] Apache.org. URL: https://storm.apache.org/. Accessed January 26, 2022
[5] Apache.org. URL: https://giraph.apache.org/. Accessed January 26, 2022
[6] Magnitude.com. What is ODBC. URL: https://www.magnitude.com/blog/what-is-odbc. Accessed January 26, 2022
[7] Wikipedia.org. Database Connectivity. URL: https://en.wikipedia.org/wiki/Java_Database_Connectivity. Accessed January 26, 2022
Category:





