
November 06, 2025
LangChain vs. LlamaIndex: Strategic Framework Selection Guide for AI Leaders (2025)
Author:

CEO & Co-Founder
Reading time:
24 minutes
As enterprises accelerate AI adoption, selecting the right orchestration framework has become a strategic imperative. This guide provides AI managers, Heads of Innovation, and Chief Data Officers with an updated, decision-focused comparison of two leading platforms for building production-grade AI applications:
- LangChain Ecosystem (LangChain + LangGraph) – One unified platform
- LlamaIndex – Separate competing framework
Note: LangChain and LangGraph are not separate frameworks—they are components of a single platform created by the same team:
- LangChain = The foundational library with integrations, prompts, and basic chains
- LangGraph = The advanced orchestration layer built ON TOP of LangChain for production agents
Think of LangGraph as LangChain 2.0 – the production-ready evolution. When we reference “LangChain” in this document, we mean the entire ecosystem including LangGraph.
Key Takeaways
- The LangChain ecosystem reached 1.0 stability in October 2025, with LangGraph as the recommended approach for new implementations
- LangGraph Platform (now LangSmith Deployment) is generally available with deployments by 800+ companies including Uber, LinkedIn, and Replit
- LlamaIndex has evolved into a commercial platform (LlamaCloud) with enterprise features, while maintaining its open-source framework
- Strategic Recommendation: LangChain ecosystem for complex, multi-agent production systems; LlamaIndex for document-centric, retrieval-focused applications
Large Language Models (LLMs) have continued to evolve and improve over the years, and so have the frameworks and platforms designed to support their development and implementation.
Two such frameworks, LangChain (including its production-focused extension LangGraph) and LlamaIndex, have emerged as leading options for those looking to improve the performance and functionality of these models.
Both tools offer unique features, capabilities, and approaches when it comes to building robust applications with large language models.
This post will provide an in-depth review of the main differences between the LangChain ecosystem and LlamaIndex, highlighting their strengths and weaknesses to help you make an informed decision on which framework best suits your needs.

Market Context: The AI Agent Revolution
The landscape has shifted dramatically since 2024. The LangChain ecosystem saw 220% growth in GitHub stars (119k) and 300% increase in downloads from Q1 2024 to Q1 2025, with 40% of users now integrating vector databases for agent memory. Enterprise adoption is accelerating, with performance quality identified as the top challenge in LangChain’s State of AI Agents survey.
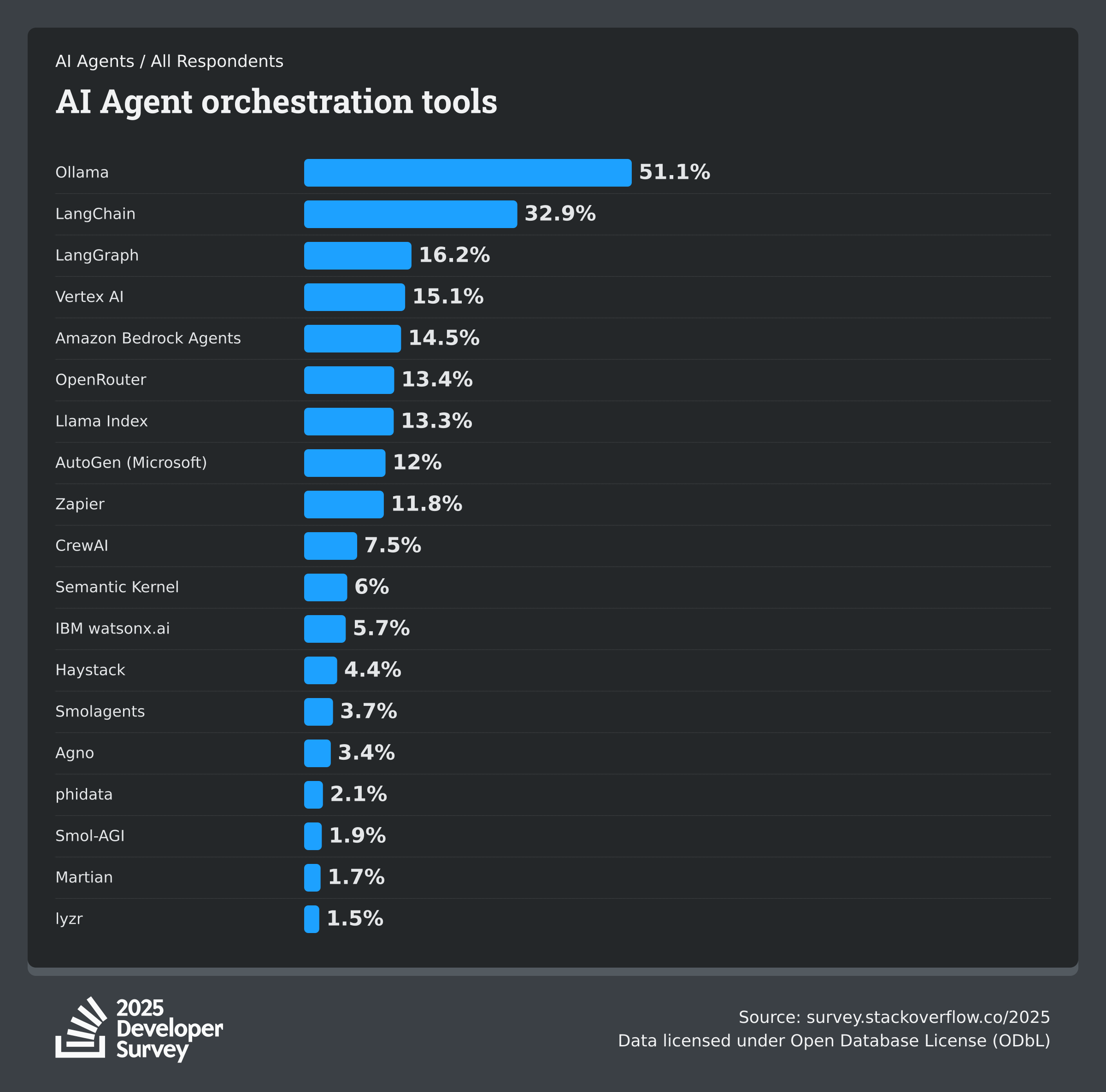
What Changed in 2025:
- Production-first architecture becoming non-negotiable
- Multi-agent orchestration replacing simple chain-based workflows
- Enterprise security and observability as baseline requirements
- Shift from prototyping frameworks to production platforms
Note on LangChain Evolution:
The LangChain team built LangGraph as the production-ready successor to their original “chains and agents” approach. LangGraph addresses feedback about scaling challenges by providing lower-level control and stateful orchestration. Both are maintained by the same team and work together seamlessly.
What is LangChain?
It’s basically an open-source and dynamic framework ideally designed to simplify the creation of data-aware and agentic applications by Large Language Models (LLMs).
This framework provides a set of versatile features and functionalities that make it easy to work with LLMs such as OpenAI’s GPT-3, BERT, T5, and RoBERTa. Whether you’re a beginner or a seasoned developer, LangChain is the ideal tool for creating LLM-powered applications and prototyping.
Important Note on LangChain and LangGraph:
LangChain and LangGraph are not separate competing frameworks – they are part of the same ecosystem created by the same team.
LangChain provides the foundational components (integrations, prompts, memory, basic chains), while LangGraph is the production-ready orchestration layer built on top of it. Think of LangGraph as LangChain 2.0, designed specifically for building stateful, production-grade agents.
As of 2025, LangGraph is the recommended approach for new agent implementations, while legacy LangChain chains remain supported.
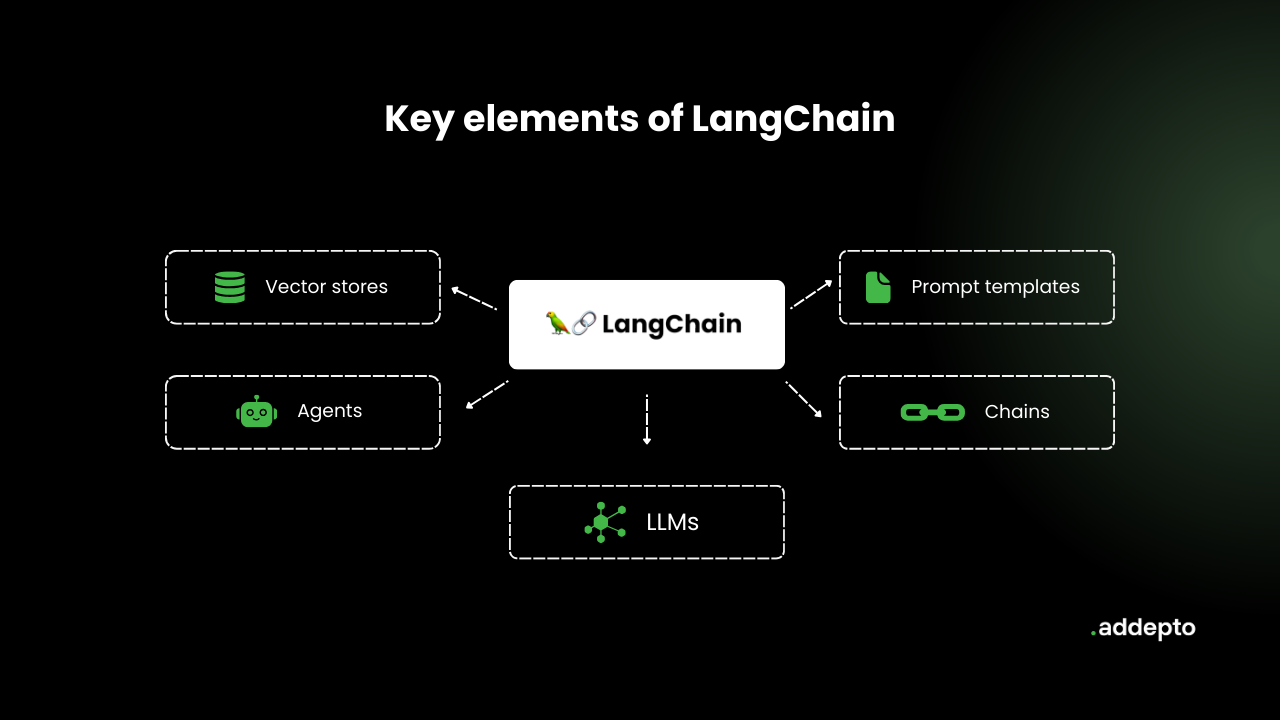
The LangChain ecosystem is made up of six core components, each with its own unique features and benefits.
Schema
Schema basically refers to the fundamental data types, structure, and organization. The Schema defines the various types of data, their relationships, and how they’re represented across the codebase. It ensures consistent handling and efficient communication between components within the framework.
Models
This component serves as the powerhouse of all AI-driven applications. LangChain models are divided into three main categories:
Large Language Models (LLMs)
Large Language Models (LLMs) are machine learning (ML) models trained on massive amounts of data to understand and generate human-like text. Within this framework, LLMs are tailored to operate seamlessly with textual data, serving as both input and output.
Chat Models
Whether provided by HuggingFace, OpenAI, Cohere, or any other AI research organization, chat models are quite similar to language models. The only difference is that chat models work with message objects instead of textual data.
Chat models usually process a series of messages in order to produce message outputs, thus creating well-structured interactions among users.
Overall, there are three types of message objects, namely HumanMessage, SystemMessage, and AIMessage. Message objects are basically coverings around text messages that do not have any special effects on their own but help distinguish various entities in a conversation.
For best results, it’s highly recommended to use HumanMessage for text input by a human, AIMessage for texts generated by the chat model, and SystemMessage to offer context to a chat model on how it should respond to a given text in a conversation.
Embedding Models
Embedding models in LangChain are used to create vector representations for texts. These models accept text inputs and convert them into a vector of floating numbers, thus effectively converting human language into numeric values. The most common application of embedding models is in semantic search, where query embedding is usually compared to embeddings of various documents.
Prompts
A prompt is simply an instruction for an LLM that elicits a desired response. In some cases, the generated response may be different depending on how the user phrased the prompt. The prompt component within this framework enables users to create tailored queries and prompts for large language models.
The overall simplicity in crafting prompts allows users to generate context-aware and informed responses. Whether you’re looking to extract specific information from a text, generate a creative text, or even engage in natural language conversations with a computer, LangChain’s prompt capabilities are vital.
Indexes
LangChain’s indexes play a vital role in efficient information retrieval. This component is ideally designed to retrieve documents quickly and intelligently from a vast external knowledge base. Indexes are particularly important for LLM-powered applications that require real-time access to huge datasets, such as chatbots, search engines, and content recommendation systems.
The main items for building this framework’s index component include:
- A tool for loading documents
- A tool for creating embedding vectors for those documents
- A tool that will keep track of those documents and vectors on the go
Memory
Any reliable conversational system must have the ability to store and access historical messages, as it is vital for effective interactions. LangChain excels in this aspect by having an efficient memory component that ensures Large Language Models can store and retrieve chat history, thus resulting in more coherent and contextually-aware responses.
This component ensures that all incoming queries are not processed in isolation but are rather cross-referenced with prior information/interactions.
LangChain’s memory objects can either be passed around in chains or used alone to investigate the history of interactions, provide a summary, extract, and even show details from archived entities when mentioned in a new interaction.
Chains
The name of this framework is a fusion of ‘Lang’ and ‘Chain’—chains are an important part of the LangChain framework. Chains essentially link multiple components and create something more effective. That said, the chain component represents the orchestration of complex workflows of LLM-powered applications within the framework.
With the help of this component, users can create sequences of instructions or interactions with language models, thus automating various processes. This is particularly beneficial for tasks that involve multiple steps, informed decision-making, and dynamic content generation.
Note: While chains were the original orchestration method in LangChain, LangGraph now provides a more powerful alternative for complex workflows. LangGraph uses stateful graph structures instead of linear chains, offering better control for production environments. For new projects in 2025, LangGraph is recommended over traditional chains.
Agents and Tools
Regardless of how sophisticated or advanced they are, LLMs are often limited to the data they were trained on. For this reason, you cannot count on an LLM to provide you with accurate information regarding something like tomorrow’s weather forecast, recent breaking news, or a prediction for a football game scheduled to take place later this week.
This is unless you integrate the LLM with another tool like the National Weather Service (NWS) API, which can read the available data and subsequently generate a response for you.
This is where the agents and tools component comes in. Agents are basically software entities that interact with LangChain and its components. They often represent external knowledge bases, users, and other AI models needed to facilitate effective communication and data exchange within the LangChain framework. Unlike chains that assume all tools within LangChain must be used, agents decide the most relevant tools for each query and only use those tools for as long as they require them.
Notably, agents and tools have a wide variety of functionalities that help in building and executing high-quality LLM-powered applications. These functionalities include pre-processing data for efficient LLM consumption, managing conversations, connecting LangChain with APIs or external databases, triggering workflows within LangChain, performing query transformations, maintaining context across interactions, and post-processing outputs to ensure they meet task goals.
Generally, agents and tools within the LangChain framework exist to enable users fine-tune their interactions with LLMs and help developers create diverse LLM-powered applications with ease.
The LangChain Ecosystem: 2025 Platform Architecture
The LangChain ecosystem has transformed from a developer toolkit into a comprehensive enterprise AI platform. LangChain provides the foundation, while LangGraph provides the production orchestration layer – together they form one unified solution. The platform is battle-tested by companies like Uber, LinkedIn, and Klarna in production environments.
Platform Components
1. LangChain Core (Foundation – Open Source)
- Promoted to 1.0 with no breaking changes, containing 1000+ integrations with providers like OpenAI and Anthropic
- New standardized message content supporting reasoning, citations, server-side tool calls across all providers
- Model-agnostic architecture preventing vendor lock-in
- Role: Provides building blocks; most developers now use these through LangGraph rather than directly
2. LangGraph (Production Layer – Open Source)
- This is the recommended way to build with LangChain in 2025
- Node-level caching, deferred nodes for map-reduce workflows, and type-safe streaming
- Stateful, cyclical graph structures replacing linear chains
- Built from first principles for production readiness, prioritizing control and durability over ease of getting started
- Evolution Note: LangGraph was created by the LangChain team as a “reboot” to address scaling feedback from the original framework
3. LangSmith Deployment (Management Platform – Commercial)
- Nearly 400 companies deployed agents since beta launch in June 2024
- Available through AWS Marketplace with full VPC deployment options via Helm charts
- Three deployment models: Cloud (SaaS), Hybrid (SaaS control/self-hosted data), Fully Self-Hosted
- Integrates with both LangChain and LangGraph for observability and deployment
Enterprise Production Capabilities
Observability & Governance
- Deep visibility with detailed tracing, real-time monitoring, and quality tracking for auditability
- Pre-deployment testing and continuous feedback on production traffic
- RBAC, workspaces, and centralized agent management
Scalability Architecture
- Horizontally-scaling servers, task queues, built-in persistence, intelligent caching, and automated retries
- Long-term memory APIs for personalized user experiences
- Background job processing for research-style workflows
Limitations of LangChain
- Learning Curve: LangGraph, while more production-ready, has a steeper learning curve compared to the original LangChain chains. Organizations need to invest in training and building expertise to use it effectively.
- Complexity for Simple Use Cases: For straightforward applications that don’t require complex state management or multi-step processes, the framework’s sophisticated orchestration capabilities may be overkill, adding unnecessary overhead.
- Historical Stability Issues: While the 1.0 release addresses this, LangChain previously experienced frequent breaking changes between versions, requiring teams to refactor code regularly. Organizations using older versions should plan migration strategies.
- Engineering Investment Required: The framework requires dedicated AI engineering resources to implement effectively. It’s not a low-code solution, making it less suitable for teams without technical AI expertise.
What is LlamaIndex?
Previously known as GPT Index, LlamaIndex is a data framework specifically designed to support and enhance the capabilities of LLMs. This framework primarily focuses on ingesting, structuring, and accessing private or domain-specific data, thus offering a simple interface for indexing and retrieval of relevant information from huge textual datasets.
Additionally, LlamaIndex offers a wide variety of tools and user-friendly features that facilitate the seamless integration of private or domain-specific data into LLMs.
This framework usually excels in use cases where precise queries and high-quality responses are vital. As a result, LlamaIndex is the ideal tool for text-based search, as well as for situations where generating accurate and contextually aware responses is important.
Overall, this framework’s main goal is to improve document management in organizations with the help of advanced technology, thus providing a simple and efficient way of searching, organizing, and summarizing documents using LLMs and advanced indexing techniques.
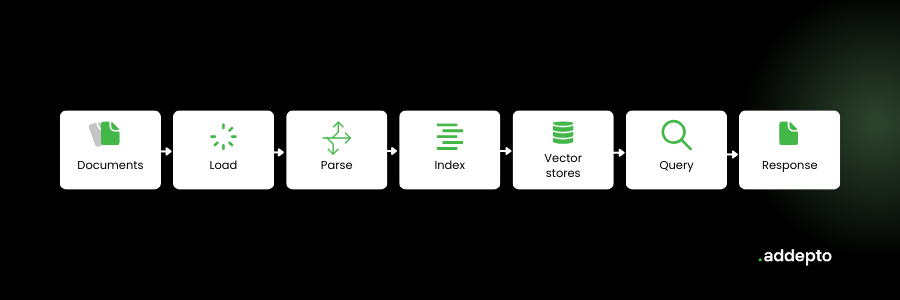
Here is a detailed breakdown of the various components that make up LlamaIndex:
Querying
Within the LlamaIndex framework, querying is all about how a user requests information from the system. Generally, it focuses on optimizing the execution of queries by providing desired results within the shortest time possible. These capabilities make the framework invaluable in various LLM-powered applications where fast information retrieval is paramount, like search engines and real-time chatbots.
That said, querying an index graph within this framework involves two major tasks. First, a collection of nodes relevant to the query are fetched. Second, a response_synthesis module is completed, using the collection of nodes and the original user query to generate an accurate and coherent response. Notably, the relevance of a particular node is usually based on the index type.
Relevant nodes can be retrieved in two different configurations, namely, list index and vector index. List index querying basically uses all the nodes in the list to generate the desired response. On the other hand, vector index querying relies on the similarity between the query vector and the indexed vectors to generate a response. In vector index querying, only the nodes that have surpassed a certain relevance threshold to the user query are retrieved and sent to the response_synthesis model.
Response Synthesis
Response synthesis simply refers to the manner in which the LlamaIndex framework generates and presents data or responses to user queries. This process is optimized to generate concise, coherent, and contextually relevant responses. Therefore, all the responses generated by this process are accurate and presented in a way that is easy for all users to comprehend. The main goal of response synthesis is to ensure users receive accurate responses without unnecessary jargon.
Composability
One of the best things about LlamaIndex is its ability to compose an index from other indexes. Composability within this framework refers to utilizing modular and reusable components to create complex queries and workflows. Thanks to this feature, users can create complex queries by simply splitting them into smaller, manageable parts.
Composability is particularly useful when you need to search and summarize multiple diverse data sources. Instead of going over every data source individually, you can simply create a separate index over every data source and subsequently create a list index over the multiple indexes. This will help create concise and informative summaries in the shortest time possible.
Data Connectors
It’s possible that the data you’re using to build an LLM-powered application is not contained in a simple text file. You may have the data stored in various sources, including confluence pages, PDF documents on your USB flash drive, or even Google Workspace documents on the cloud. Loading data from all these sources will take a lot of time and effort. Fortunately, LlamaIndex is here to assist.
LlamaIndex offers a variety of data connectors and loaders available on LlamaHub, a registry of open-source data connectors. These data connectors allow you to access and ingest data from its native source and format, thus eliminating the need for time-consuming and tedious data conversion processes.
With the help of these data connectors, you can load data from all types of sources, including external databases, APIs, SQL databases, PDFs, and other datasets. This facilitates seamless integration of data, which is vital for developing data-intensive LLM-powered applications. Moreover, data connectors within the LlamaIndex framework offer other benefits like enhancing data quality, improved data performance via caching, and enhanced data security through encryption.
Query Transformations
Query transformation refers to the ability to modify a user’s questions on the go to help generate more accurate answers. This is a great feature when it comes to handling complex queries. The main idea behind query transformation is to rephrase the user’s question into simpler terms or break down the question into smaller, manageable parts.
This LlamaIndex component allows you to adapt and refine your question as required during runtime. As a result, you can easily adjust your question to meet changing needs without actually reconfiguring the entire system. This level of flexibility is important in scenarios where the query requirements are subject to constant change.
Node Postprocessors
In LlamaIndex, node postprocessors always come after data retrieval and before response_synthesis to help filter the set of selected nodes. They allow users to adjust and refine responses to their queries. This makes the LlamaIndex component crucial when dealing with data that needs transformation, structuring, or further processing after retrieval.
Storage
Storage is an important aspect of developing LLM-powered applications. Developers need sufficient storage for vectors, nodes, and the index itself. Storage across LlamaIndex primarily focuses on efficient data storage and quick retrieval. The framework’s storage component is responsible for data management and ensuring relevant information can be retrieved easily.
LlamaIndex: 2025 Platform Architecture
LlamaIndex has evolved into a specialized platform focused on document understanding and retrieval-augmented generation (RAG). The company differentiates between its open-source framework and commercial platform.
Platform Components
1. LlamaIndex Framework (Open Source)
- Free Python and TypeScript library with 160+ data source connectors
- Core strength in indexing, retrieval, and query optimization
- Growing ecosystem of 650+ community packages
2. LlamaCloud (Commercial Platform)
- Managed platform for document workflows including agentic parsing, extraction, and indexing with 10,000 free credits monthly
- Pricing tiers: Free ($0), Starter ($50/month with 50K credits), Pro ($500/month with 500K credits), and Custom Enterprise
3. LlamaParse (Document Processing Engine)
- Support for GPT-4.1 and Gemini 2.5 Pro models delivering state-of-the-art parsing accuracy
- Automatic orientation detection and skew correction for scanned documents
- Handles complex PDFs, PowerPoints, and Word documents
Recent Enterprise Features (2025)
Multi-Agent Capabilities
- AgentWorkflow for creating multi-agent systems with flexible agent types and built-in state management
- Memory API combining short-term chat history and long-term memory with plug-and-play blocks
Production Tools
- FlowMaker visual agent builder for creating agents without code
- Typed state support with Pydantic validation for robust workflow management
- NotebookLlaMa as open-source alternative to NotebookLM with 1,000+ GitHub stars
Enterprise Integrations
- Azure AI Foundry Agent Service support with first-class LlamaIndex integration
- Google Cloud Gemini integration with production-ready RAG patterns
- Model Context Protocol (MCP) server integration
Proven Enterprise Applications
Boeing’s Jeppesen subsidiary saved approximately 2,000 engineering hours using LlamaIndex. StackAI leverages LlamaCloud for high-accuracy retrieval in enterprise document agents. Other notable use cases include:
- Legal knowledge graph generation transforming contracts into queryable databases
- Financial document analysis and structured data extraction
- Hybrid RAG + Text2SQL routing between databases and vector search
- RFP response automation reducing hours to minutes
The Main Differences Between LangChain and LlamaIndex
Although both the LangChain ecosystem and LlamaIndex share some overlap and can be used together in building robust and versatile LLM-powered applications, they’re quite different. Here are some of the key differences between the two platforms:
Core Functionality
The LangChain ecosystem is a multi-purpose framework that provides developers with a set of tools, functionalities, and features needed to create and deploy a wide variety of LLM-powered applications. The framework’s main emphasis is to streamline the development process for developers of all skill levels, with LangGraph providing production-ready orchestration for complex agent workflows.
On the other hand, LlamaIndex is specifically designed to create search and retrieval applications. It provides a simple interface for indexing and retrieval of relevant documents, thus maintaining its core focus of ensuring efficient data storage and access for LLMs.
Use Cases
The LangChain ecosystem is an adaptable and versatile framework ideally designed for creating LLM-powered applications that require advanced AI capabilities. Plus, the platform’s excellent memory management and orchestration capabilities (especially through LangGraph) make it best suited for maintaining long and contextually relevant conversations with complex workflows. Some of the most common applications include text generation, language translation, text summarization, multi-agent systems, and text classification.
In contrast, LlamaIndex is well-suited for scenarios where text search and high-quality responses are the top priorities. The most common use cases of LlamaIndex include content generation, document search and retrieval, RAG (Retrieval-Augmented Generation) applications, chatbots focused on knowledge bases, and virtual assistants.
Pricing and Availability
If you’re looking for a cost-effective platform for building LLM-driven applications, both frameworks offer open-source options. The LangChain ecosystem (including both LangChain and LangGraph) is open-source and free, with source code available on GitHub. However, LangSmith (the commercial observability and deployment platform) is subscription-based with Plus and Enterprise tiers.
LlamaIndex also has a dual model: the open-source framework is free, while LlamaCloud is the commercial managed platform with credit-based pricing starting at $50/month. The pay-as-you-go model means costs can vary significantly based on document processing volume.
Production Readiness
LangChain Ecosystem: With the 1.0 release and LangGraph’s maturity, the platform has proven production readiness with 400+ companies deploying agents. It offers comprehensive observability through LangSmith, three deployment options (Cloud, Hybrid, Fully Self-Hosted), and enterprise features like RBAC and workspace isolation. Major enterprises like Uber, LinkedIn, and Klarna use it for mission-critical applications.
LlamaIndex: While growing in production deployments, LlamaIndex has a smaller enterprise track record compared to LangChain. The framework’s workflows are stateless by default (state management is explicit rather than built-in), and multi-agent orchestration is less mature. However, for document-centric RAG applications, it offers faster time-to-value with managed services and easier learning curve.
Decision Framework for AI Leaders
By Strategic Objective
| Objective | Recommended Framework | Key Consideration |
|---|---|---|
| Build complex autonomous agents | LangChain Ecosystem (use LangGraph) | Production-ready orchestration with proven enterprise scale |
| Implement document Q&A systems | LlamaIndex | Specialized document parsing and retrieval optimization |
| Rapid POC/MVP development | LlamaIndex | Lower learning curve, faster initial results |
| Multi-agent collaboration | LangChain Ecosystem (use LangGraph) | Purpose-built debugging, state management, and HITL interrupts |
| Customer service automation | LangChain Ecosystem (use LangGraph) | Comprehensive observability and proven ROI |
| Internal knowledge management | LlamaIndex | Strength in indexing diverse document types |
| Vendor-agnostic AI strategy | LangChain Ecosystem | Standardized abstractions across 1000+ provider integrations |
Security and Compliance Considerations
Enterprise Security Features
LangChain Ecosystem (LangChain + LangGraph + LangSmith):
- Self-hosted deployment options enable complete data residency control for both LangGraph applications and LangSmith observability
- Full VPC deployment via AWS Marketplace with no data leaving customer infrastructure
- RBAC and workspace isolation in LangSmith
- Open-source LangChain and LangGraph code can be audited and secured by your team
- Note: LangSmith had a security vulnerability in June 2025 (now fixed) exposing API keys; self-hosting recommended for sensitive deployments
LlamaIndex/LlamaCloud:
- Data encrypted in transit and at rest on secure cloud tenant
- Limited self-hosting options compared to LangChain
- Primarily SaaS-based architecture
Final Thoughts
Any LLM-powered application can harness the benefits of both the LangChain ecosystem and LlamaIndex, depending on requirements. That said, your choice between the platforms will mainly depend on your specific needs and the objectives of your LLM project.
The LangChain ecosystem (LangChain + LangGraph) excels at offering flexibility, versatility, and advanced orchestration capabilities, making it suitable for complex, multi-agent, context-aware applications. It’s the better choice for organizations with dedicated AI engineering teams building mission-critical production systems that require comprehensive observability and control.
On the other hand, LlamaIndex is excellent at fast data retrieval, document processing, and generating concise responses from knowledge bases. This makes it ideal for document-driven applications such as chatbots and virtual assistants, content-based recommendation systems, and question-answering systems. It’s particularly suitable for teams that want rapid time-to-value and don’t have extensive AI engineering resources.
FAQ: LangChain vs. LlamaIndex
What is LangChain?
LangChain is an open-source framework designed to simplify the creation of data-aware and agentic applications with Large Language Models (LLMs). It offers versatile features for working with models like GPT-3, BERT, T5, and RoBERTa, making it ideal for both beginners and seasoned developers. LangGraph, built by the same team, is the production-focused extension that provides advanced orchestration for complex agent workflows.
What unique features does LangChain offer?
The LangChain ecosystem offers six main components including Schema for data organization, Models for AI applications, Prompts for tailored queries, Indexes for efficient information retrieval, Memory for storing chat history, and Chains for orchestrating complex workflows. LangGraph adds stateful graph-based orchestration, human-in-the-loop interrupts, and time-travel debugging for production environments.
What is LlamaIndex?
Previously known as GPT Index, LlamaIndex is a data framework focused on ingesting, structuring, and accessing private or domain-specific data for LLMs. It simplifies indexing and retrieval of information, making it perfect for text-based search and generating accurate responses from document collections.
What are the core components of LlamaIndex?
LlamaIndex’s components include Querying for optimized information requests, Response Synthesis for generating coherent responses, Composability for creating complex queries, Data Connectors for seamless data integration from 160+ sources, Query Transformations, Node Postprocessors for refining responses, and efficient Storage solutions.
How do LangChain and LlamaIndex differ?
The LangChain ecosystem is a multi-purpose framework with a wide range of tools for various LLM-powered applications, focusing on flexibility and advanced AI capabilities, with LangGraph providing production-ready orchestration. LlamaIndex is specialized for search and retrieval applications, emphasizing fast data retrieval and document processing for RAG applications.
What are typical use cases for LangChain and LlamaIndex?
The LangChain ecosystem is suitable for multi-agent systems, complex automation workflows, language translation, text summarization, and classification. LlamaIndex excels in document search and retrieval, RAG applications, knowledge-base chatbots, and virtual assistants focused on answering questions from document collections.
Are LangChain and LlamaIndex free to use?
Both frameworks offer open-source versions that are free to use. LangChain and LangGraph are open-source and available on GitHub. However, LangSmith (the commercial observability and deployment platform for the LangChain ecosystem) is subscription-based. LlamaIndex’s open-source framework is free, but LlamaCloud (the managed commercial platform) has credit-based pricing starting at $50/month.
Can LangChain and LlamaIndex be used together?
Yes, depending on your LLM project’s specific needs and objectives, leveraging the strengths of both frameworks can lead to the development of sophisticated LLM-driven applications. A common pattern is using LangGraph for agent orchestration while utilizing LlamaIndex’s data connectors and retrieval capabilities for document processing.
What are the disadvantages of LangChain?
The LangChain ecosystem has a steeper learning curve, especially for LangGraph, requiring investment in training and expertise. It may be unnecessarily complex for simple use cases. Historically, it suffered from breaking changes between versions, though the 1.0 release (October 2025) addresses this with a stability commitment. It requires dedicated AI engineering resources and is not suitable for teams without technical expertise.
What are the disadvantages of LlamaIndex?
LlamaIndex may struggle with scalability for large-scale applications and relies heavily on external services that can fail. It offers limited customization options for specific use cases and lacks some advanced orchestration features found in LangGraph. The pay-as-you-go credit model in LlamaCloud can create unpredictable costs. Its multi-agent capabilities are less mature compared to LangGraph, and workflows are stateless by default.
Will LangGraph replace LangChain?
No, LangGraph will not replace LangChain – they are complementary parts of the same ecosystem. LangGraph is built on top of LangChain and uses its components. Think of LangGraph as the production-ready evolution of LangChain’s original chains concept. LangGraph is now the recommended approach for new agent implementations (as of 2025), while LangChain provides the foundational components and integrations. Legacy LangChain chains remain supported through the langchain-legacy package.
This article is an updated version of the publication from Dec. 20, 2023. Updated November 2025 to reflect the LangChain 1.0 release, LangGraph’s production maturity, and LlamaIndex’s evolution into LlamaCloud.
References
[1] Techtarget.com. The Best LLMs. URL: https://www.techtarget.com/whatis/feature/12-of-the-best-large-language-models. Accessed on December 18, 2023
[2] Linkedin.com. What are the Top AI Research Organizations? URL: https://www.linkedin.com/pulse/what-top-ai-research-organizations-ai-news. Accessed on December 19, 2023
[3] Weather.Gov. API Web Service. URL: https://www.weather.gov/documentation/services-web-api. Accessed on December 19, 2023
[4] IBM.com. Encryption. URL: https://www.ibm.com/topics/encryption. Accessed on December 19, 2023
[5] Jaydevs.com. Software Developer Levels. URL: https://jaydevs.com/software-developer-levels/. Accessed on December 19, 2023
Category:





