
December 22, 2025
DataOps Platforms: Top 10 in 2026
Author:

CSO & Co-Founder
Reading time:
15 minutes
According to analysis of McKinsey Global Institute findings, data‑driven organizations are 23 times more likely to acquire customers, six times more likely to retain them, and 19 times more likely to be profitable than peers that do not effectively leverage data.

Data Engineering Service – CTA
This is where a modern DataOps platform comes into play, providing a streamlined, observable, and automated approach to managing data so businesses can make faster, data‑driven decisions with higher confidence.
Over the past few years, the total amount of data captured, created, copied, and consumed has rapidly increased. Recent estimates indicate that global data volume is projected to reach around 181 zettabytes by 2025, up sharply from tens of zettabytes just a few years earlier. For this reason, it has become increasingly difficult for businesses to manage data effectively within the required time frames and quality expectations. DataOps addresses this challenge by combining agile, DevOps‑inspired practices, automation, and strong data governance to keep data pipelines reliable, observable, and scalable.
Read on to learn more about DataOps platforms and how you can integrate these practices into your business. You’ll also find an updated overview of leading DataOps‑related platforms you can consider for different parts of your data stack.
Key Takeaways: DataOps Platforms & Practices
- Data-driven performance depends on operationalizing data, not just collecting itOrganizations that outperform their peers do so because they can reliably turn data into decisions. DataOps provides the processes, automation, and governance needed to shorten time-to-insight and increase trust in data at scale.
- DataOps is as much about culture and collaboration as technologySuccessful DataOps adoption requires tight collaboration between data engineers, analysts, scientists, and business teams. Shared workflows, version control, and visibility into changes are critical to avoiding silos and improving decision quality.
- Automation and repeatability are essential at modern data scaleWith global data volumes exploding, manual pipeline management no longer works. DataOps platforms automate ingestion, testing, deployment, monitoring, and rollback, enabling teams to scale analytics reliably without proportional increases in effort.
- Observability, governance, and security define platform maturityModern DataOps platforms are evaluated not just on orchestration, but on end-to-end observability, lineage, compliance, and access control. These capabilities ensure data remains trustworthy, explainable, and safe as pipelines and users scale.
- The DataOps platform landscape is shifting toward AI-ready operationsLeading platforms are evolving beyond pipeline management into AI-driven observability, cost optimization, real-time activation, and GenAI data readiness, positioning DataOps as foundational infrastructure for enterprise AI, not just analytics.
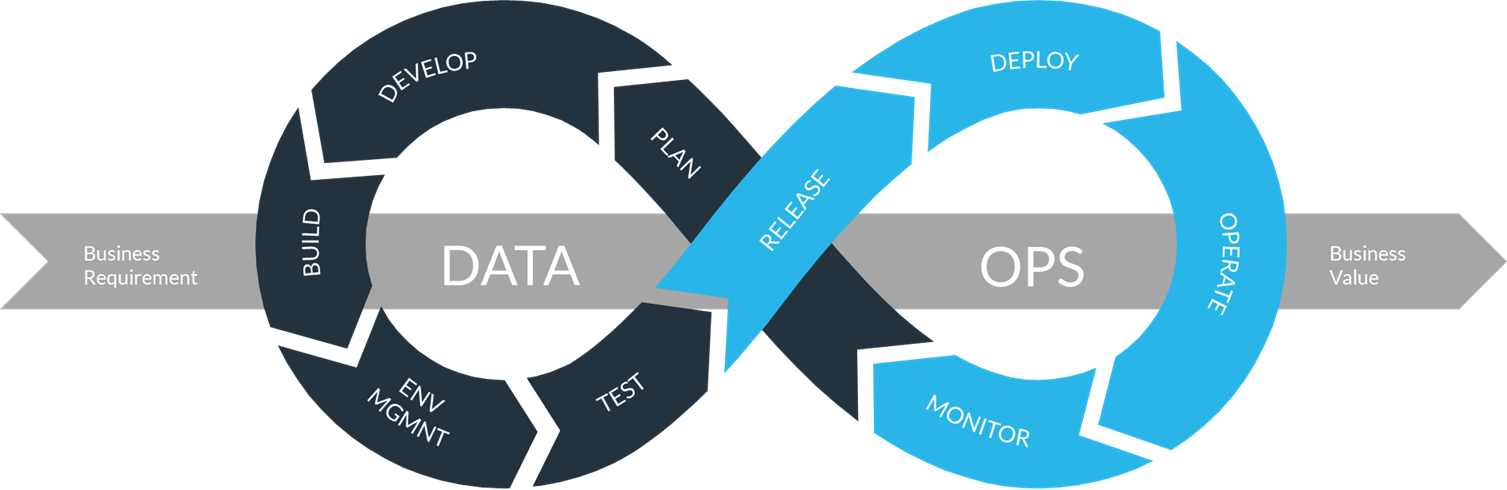
What is DataOps?
DataOps is a set of practices, cultural norms, and technologies that apply agile development, DevOps, and lean principles to data analytics and data engineering, with the goal of delivering high‑quality insights quickly and reliably.
While authors such as Lenny Liebmann helped introduce and popularize the term, it has been strongly championed by the DataKitchen team (Chris Bergh and colleagues) as a way to industrialize analytics delivery. It combines process‑oriented data management methods with continuous testing, monitoring, and collaboration to enhance data quality and reduce cycle time, while fostering a culture of continuous improvement in data analytics.
DataOps intends to simplify data management by breaking down large volumes of data and gathering fragmented information in a well‑structured, auditable manner that is fast, reliable, and scalable.
The main purpose of DataOps is to maximize the business value of data by increasing trust, shortening time‑to‑insight, and improving customer satisfaction through better, more timely decisions.
To achieve this, DataOps focuses on the following key areas.
Source: snowflake.com
Collaboration
With the ever‑rising demand for faster data analysis, it is now common for various data professionals to work on the same project simultaneously. For this to succeed, a robust collaboration model is needed across data engineers, analysts, data scientists, and business stakeholders.
Effective team collaboration supported by shared environments, version control, and clear workflows leads to a more data‑driven culture and better decision‑making.
That said, an effective collaboration framework should be able to track changes in real time, quickly resolve conflicts, compare versions, and coordinate code, configuration, and data changes across environments.
It should also integrate with communication tools and issue‑tracking systems so that data incidents, schema changes, and business requests are visible to all relevant team members
Data quality
Good data quality is important for the success of every data‑driven business. Modern DataOps practices incorporate automated data validation, anomaly detection, schema checks, and data profiling into every stage of a data pipeline. DataOps improves data quality by making these checks repeatable, testable, and integrated into CI/CD, instead of relying solely on ad‑hoc, manual reviews.
By improving data quality and observability, businesses can detect issues earlier, reduce downtime, and make better decisions that improve their bottom line and help them attain their long‑term goals. Many DataOps teams now also define data SLAs and use monitoring dashboards and alerts to track freshness, completeness, and reliability of critical datasets
Automation
Automation is necessary for the successful implementation of a DataOps strategy. It streamlines the daily demands of managing large and complex data volumes, freeing data professionals to focus on developing better analytics and data products.
Automating the processes of collecting, transforming, testing, and deploying data and analytics minimizes errors and allows for faster turnaround times.
Typical examples include:
- automated pipeline orchestration
- test execution on code changes
- environment provisioning
- automated rollbacks when issues are detected.
As organizations adopt AI and real‑time analytics, this kind of end‑to‑end automation becomes essential to keep pace with business needs.
What is a DataOps platform?
A DataOps platform is an integrated environment that helps data teams design, orchestrate, monitor, and govern data pipelines and analytics workflows across multiple tools and technologies.
It is used by data professionals to process data and provide secure, governed environments for sharing and consuming data products.
This platform is where data coming from different sources is compiled, transformed, quality‑checked, and delivered to respective users and applications.
It orchestrates people, processes, and technology to develop trusted data pipelines for all users. In other words, it acts as a command center for DataOps processes, connecting ingestion, transformation, quality, observability, and activation layers.
A reliable DataOps platform does not only process data used for privacy, security, and compliance but also customer data, technical operations data, and every other data asset a business receives or generates from its daily operations.
It should integrate with existing data warehouses, data lakes, BI tools, and ML platforms, providing the flexibility to plug into your current stack instead of forcing a complete replacement. This way, companies can manage their entire workflows and related processes to ensure that data‑driven decisions are made consistently and transparently.
Additionally, companies can use DataOps platforms to gain on‑demand insights for making successful business decisions, for example through self‑service data access and governed data products.
Data professionals within an organization can use them to reduce infrastructure costs, improve efficiency, and increase their productivity through automation and better reuse of pipelines.
On the other hand, software development and testing teams can use DataOps‑aligned platforms and practices – such as test data management and CI/CD for analytics – to shorten development cycles and minimize errors during app development processes
Factors used to assess a DataOps platform
There are several key factors you can use to assess performance and determine the best DataOps platform depending on your needs.
These include scalability, repeatability and automation, reliability and observability, and governance and security.
Scalability
Scalability refers to the capacity of a DataOps platform to handle increasing volumes of data, the number of users, and general operational complexity. A highly scalable DataOps platform can process large volumes of data and high‑frequency events with low latency, while also scaling out to support more concurrent users and workloads.
For instance, if your company deals with online advertising or clickstream data, you need a DataOps platform that can orchestrate streaming pipelines and process terabytes of data per day across multiple cloud environments.
On the other hand, if you are dealing with smaller but highly regulated datasets, a platform that provides strong governance and predictable performance for gigabytes of critical data may be sufficient.
Even though the term “large capacity” is relative, having a DataOps tool that can properly manage your expected peak data volumes and throughput is important.
In addition, a scalable platform should support horizontal scaling, multi‑cluster or multi‑cloud deployments, and elastic resource management to control cost.
In addition to data volume, a reliable DataOps platform needs to be able to accommodate an increasing number of users. The number of people working in your organization will likely increase with time.
Therefore, you need a tool that will accommodate everyone, including business analysts, data professionals, technical support teams, implementation teams, and partnership teams, while maintaining role‑based access control and performance
Repeatability and automation
Repeatability refers to the program or system’s capacity to automate and reliably repeat tasks. The best DataOps platform should provide optimal repeatability despite different data types, sources, and formats, including APIs, message queues, databases, FTP servers, and file‑sharing services.
Since new data is added and existing pipelines are updated daily, the DataOps platform needs to support continuous deployment of improved data pipelines. Platforms capable of supporting pipeline templating, cloning, flow pauses, versioning, promotion between environments, and scheduled or event‑driven activations are particularly valuable for large‑scale operations.
The DataOps platform should also be capable of moving, developing, and testing data pipelines quickly before they get to a production environment where monitoring is required.
Besides that, it should provide real‑time alerts and recommendations where necessary. For instance, if a program error or data anomaly occurs, a DataOps platform should be able to detect discrepancies in the data in real time and notify the appropriate teams, sometimes even suggesting remediation steps.
Reliability, observability, governance, and security
Modern evaluations of DataOps platforms also emphasize reliability (uptime, SLAs), end‑to‑end observability (lineage, metrics, logs, traces), and robust governance and security (access controls, masking, tokenization, and audit trails).
Platforms like Delphix, for example, highlight capabilities such as data cataloging, lineage, masking, tokenization, and compliance support to help organizations meet regulatory and internal governance requirements.
These capabilities ensure that as pipelines scale, data remains discoverable, compliant, and protected, while stakeholders can trace how key metrics are produced and investigate issues quickly
The best DataOps platforms in 2025
In the two years between 2023 and 2025, the DataOps landscape has undergone a tectonic shift, moving from a discipline of “plumbing” to one of “intelligence.”
In 2023, teams were primarily focused on the manual effort of connecting fragmented tools and establishing basic CI/CD for data pipelines to prevent them from breaking.
By 2025, however, the rapid rise of Generative AI has forced a professional evolution. The focus has moved away from simply moving data toward the creation of high-fidelity Data Products – modular, pre-governed, and “AI-ready” assets that can be instantly consumed by autonomous agents and real-time business systems.
Today, the standard for a high-performing data team is no longer just “uptime,” but autonomous resilience. Modern platforms have shifted from reactive alerting to “Agentic Operations,” where AI-driven systems detect anomalies, manage cloud compute costs through integrated FinOps, and even suggest code fixes before a human engineer is even paged.
We are seeing a move from batch processing to sub-second data activation, turning the data warehouse from a static archive into a live engine that fuels every interaction. In short, DataOps has matured from a backend engineering utility into the essential nervous system of the AI-driven enterprise.
DataKitchen
DataKitchen is a DataOps platform that allows for automation and coordination of people, workflows, tools, and environments involved in a company’s analytics initiatives. It handles tasks such as orchestration of data pipelines, deployment, monitoring, automated testing, and environment management.
With features like parameterized testing, reusable templates, and support for parallel execution, DataKitchen helps teams implement continuous testing and monitoring for analytics, significantly reducing the time needed to detect and fix data issues in high‑volume environments.

Source: datakitchen.io
In 2023, DataKitchen was the champion of pipeline automation. By 2025, it has evolved into the industry’s leading DataOps Observability hub.
While it still handles orchestration and environment management, its primary value now lies in “Value Stream Management” – helping teams see exactly where bottlenecks occur across their entire toolchain.
K2View
K2View is an all‑in‑one platform that focuses on creating micro‑databases per business entity (such as customer or device), aggregating and transforming data from multiple source systems in real time. This architecture enables companies to serve consistent, governed data products for operational and analytical use cases.
Although K2View is often described as a data fabric or data product platform rather than a pure DataOps tool, its automation, governance, and real‑time serving capabilities make it relevant for organizations implementing DataOps principles across operational data flows.

Source: K2View
In 2025 K2view has matured from a data fabric utility into the definitive Data Product Platform. While the 2023 version focused on real-time operational use cases via “micro-databases,” the 2025 version is the backbone of Enterprise AI.
K2view is now a leader in GenAI Data Readiness. Their platform “fuses” live enterprise data with LLMs, providing the real-time context needed for Retrieval-Augmented Generation (RAG). It ensures AI agents have a 360-degree, governed view of business entities (like a customer or an order) in milliseconds.
Unravel
Unravel simplifies monitoring and optimization of data workloads across environments such as GCP, Azure, AWS, and on‑premises data centers. It helps optimize performance, automate troubleshooting, and minimize operational and cloud costs for platforms like Databricks, Spark, and other data services.

Source: Unraveldata.com
With Unravel, you can easily monitor, manage, and improve your data pipelines on‑premises and in the cloud, driving better performance in the applications that propel your business.
The platform also provides insights into KPIs and cloud migration costs, and uses AI‑driven recommendations to improve reliability and cost efficiency – capabilities that align closely with DataOps and FinOps practices.
In 2025, as cloud compute costs for Snowflake and Databricks exploded, Unravel pivoted from simple troubleshooting to autonomous cost optimization. The platform now features AI Agents that proactively detect “money leaks” and automatically suggest (or implement) SQL code rewrites and cluster resizing to keep projects within budget without sacrificing performance.
Perforce Delphix
Delphix (now part of the Perforce ecosystem) remains the gold standard for Test Data Management (TDM) but has undergone a massive transformation to support AI development.

Source: Delphix
Delphix also offers data compliance automation services for privacy regulations and a wide variety of data operations that make CD/CI workflows possible. [5]
Census
In 2023, Census was about moving data; today, it’s about making data “act” in real-time. With the launch of Census Live Syncs, the platform has moved from hourly batches to sub-second latency.
This allows marketing and sales teams to trigger actions (like a personalized email or a discount offer) based on warehouse data the very instant a customer interacts with your product.
Datafold
Datafold is a DataOps platform that helps users keep track of data flows so that they can detect and prevent data discrepancies in good time. The platform’s Data Diff feature makes it possible to test ETL code and highlight available changes as well as their impact on the produced data. Datafold can integrate seamlessly with other DataOps tools, which explains its popularity among data professionals.
In 2025, Datafold’s new AI assistant, Metis, scans every code change (Pull Request) and predicts exactly how it will impact downstream data and dashboards. It essentially acts as a “safety net,” preventing engineers from accidentally breaking a billion-dollar dashboard with a single line of SQL.
StreamSets
StreamSets allows highly skilled data professionals and visual ETL developers to collaborate on vital data engineering tasks. With its extensive features and intend-driven design, this DataOps tool helps you build data pipelines within the shortest time possible.
In fact, you can build data pipelines of your choice within minutes and deploy them to provide high-quality data for real-time analytics.
Since its integration into IBM watson, StreamSets has become the “streaming beast” for hybrid-cloud environments; its core strength is now Data Drift Protection. StreamSets pipelines are “intent-driven” – they automatically detect when a source schema changes and adjust themselves to prevent the pipeline from breaking, a feature that has become critical for feeding “always-on” AI systems.
Final thoughts: DataOps platform in business practice
With the help of a DataOps platform, it’s easier for data-and development-focused teams to work together to develop effective DataOps practices for the company’s betterment. When data is managed effectively, businesses accelerate incident responses, solve problems faster, maximize productivity, and generate more profits.
Additionally, the data pipelines will be managed, maintained, and optimized in a way that helps the organizations stay competitive in today’s fast-paced business environment.
Disclaimer: The article you have just read was originally published in 2023 and has been comprehensively revised in 2025. This update ensures that the strategies, platform capabilities, and market trends mentioned reflect the current state of the industry, including the widespread integration of AI agents, FinOps, and real-time data activation.
References:
[1] Mckinsey.com. How Customer Analytics Boosts Corporate Performance URL: https://www.mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/five-facts-how-customer-analytics-boosts-corporate-performance. Accessed April 4, 2023
[2] Statistica.com. Worldwide Data Created. URL: https://www.statista.com/statistics/871513/worldwide-data-created/. Accessed April 4, 2023
[3] Medium.com. Successful DataOps Framework for Your Business. URL: https://balavaithyalingam.medium.com/successful-dataops-framework-for-your-business-67531709a764. Accessed April 4, 2023
[4] Solarwinds.com. Improving Data Quality Through DataOps. URL: https://orangematter.solarwinds.com/2022/01/05/improving-data-quality-through-dataops/. Accessed April 4, 2023
[5] GitHub.com. URL: https://resources.github.com/ci-cd/. Accessed April 7, 2023
[6] Talented.com. Reverse ETL. URL: https://www.talend.com/resources/reverse-etl/. Accessed April 7, 2023
FAQ
How is DataOps different today than in 2023?
It has shifted from Reactive (fixing what breaks) to Autonomous (AI agents that self-heal pipelines and optimize costs).
What is "AI-Ready" data?
It is data packaged as a “product” – pre-governed, high-quality, and formatted so AI models can use it for Retrieval-Augmented Generation (RAG) without “hallucinating.”
Why is FinOps now part of DataOps?
Because unmanaged AI and cloud costs can bankrupt a project. Modern platforms now treat cost as a primary data quality metric.
Can pipelines actually fix themselves?
Yes. Top 2025 platforms use AI to detect schema changes and automatically adjust the code to keep data flowing without human intervention.
Do I need a platform if I'm not using AI yet?
Yes. The efficiency, cost-tracking, and automated testing provided by these tools are essential for standard business intelligence (BI) to remain competitive.
Category:





