
January 21, 2022
Data automation strategy: How to develop and document your data lake

Author:

CSO & Co-Founder
Reading time:
8 minutes
IT is developing at an incredible rate, and major software giants like Google and Amazon are already making significant strides in analytics, big data, and artificial intelligence. But, for any business to achieve this, it needs a flexible data automation strategy and a data lake to consolidate all its data. And that’s what we’re going to talk about in this blog post.
In the near future, this technology is predicted to account for a significant share of the overall market due to their increased application in the IT, BFSI, and retail sectors. Numerous companies are already working relentlessly to actuate novel developments in digital solutions to enhance and evaluate their businesses.
This begs the question, how can you develop and document a flexible and reliable data lake architecture? Read on to find out! But first, let’s dive into the definitions of data automation and data lakes.
What is data automation?
Data automation is the process of uploading, processing, and handling data in an open data portal automatically rather than manually. Automating your data upload processes is essential for the long-term sustainability of your data platform. It not only saves money and time but also improves business efficiency as it reduces errors through data validation.
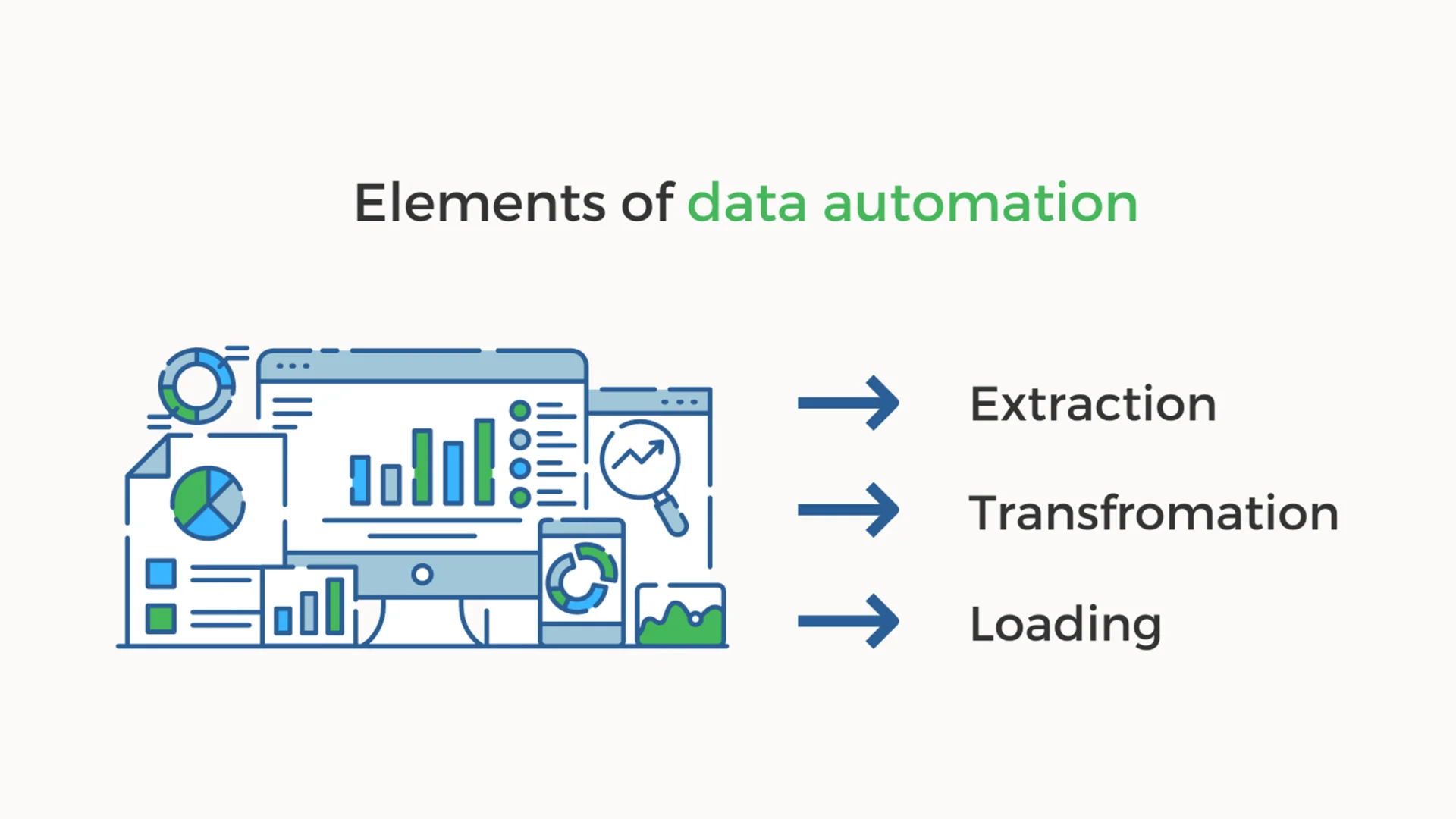
There are three elements of data automation. They comprise the so-called ETL process, which includes:
- Extraction: It’s the process of extracting data from one or numerous source systems.
- Transformation: It’s the process of transforming data into the necessary structure. It could also include things like changing state abbreviations to the full state name.
- Loading: As the name suggests, loading is basically the process of loading data into the final system, such as an open data portal.
Read more about Building a data lake on cloud (AWS, Azure, GCP)
What is a data lake?
A data lake is a centralized storage platform that allows you to store all your structured and unstructured data at any scale and in any file format. With a data lake, you can store big data exactly as it is without having to structure it or run it through different types of adjustments and analytics like visualizations and dashboards (like you would with a data warehouse).
Moreover, unlike traditional data warehouses, data lakes use flat architecture to store data, mainly in object storage or files. This gives users more flexibility when it comes to big data management, usage, and storage.
According to an Aberdeen survey, organizations that implement a data lake outperform similar companies by 9% in organic revenue growth. These companies can perform new types of data analytics over new sources like data from click-streams, log files, social media, and connected internet devices stored in the data lake.
This enables the organizations to identify and act upon opportunities that fuel business growth by boosting productivity, attracting and retaining customers, and making informed decisions. As you build a database and analytics platform, you need to consider several key capabilities of a data lake, including:
- Data movement: It enables you to import any amount of data in real-time. The data is collected from multiple sources and moved into the data lake in its original format. This enables you to scale data of any size while saving time on defining data schema, structures, and transformations.
- Machine learning: It allows your organization to develop machine learning models that forecast likely outcomes and suggest actionable insight to achieve the desired result.
- Analytics: It allows players in different departments in your organization, for example, business analysts, data developers, and data analysts, to access data with their preferred analytic tools and framework. This includes open-source frameworks such as Petro, Apache Hadoop, Apache Spark, and commercial offerings from business intelligence and data warehouse vendors. With a data lake, you can also run analytics without moving your data to a separate analytics system.
What is the real value of a data lake?
The sheer ability of data lakes to harness big data from multiple sources in a short time frame empowers users to analyze data in different ways, leading to a better and faster decision-making process. Here are a few areas where this technology can add value to your company.
Increased operational efficiency
The internet of things (IoT) enables you to collect data on processes like manufacturing through data from connected internet devices in real-time. With a data lake, you can easily store and analyze IoT-generated data to discover better ways to reduce operational costs and increase the quality of products and services.

Improved customer interactions
It enables you to combine customer data from a CRM platform with social media analytics. With this data, you can better understand important customer details like the most profitable customer cohort, which promotions and rewards increase loyalty, and what causes the customer churn.
Improved R&D innovations
It can help your RND teams test their hypothesis, refine their assumptions, and assess results. This is especially helpful when it comes to choosing which materials in your product design can result in better performance. It also helps organizations understand customers’ willingness to pay for different attributes of a product.
How to create a data lake for your business?
Creating a data lake that is efficient enough to allow different data sets to be added consistently over a long period requires a process of automation. But, to move in this direction, you first have to select a data lake technology along with the relevant tools needed to set up the data lake solution. Here are the steps that you should follow:
Set up a data lake solution
If you plan on setting up your data lake in a cloud, you can deploy it in AWS[1] since it enables you to utilize serverless services underneath without substantial upfront costs. Additionally, a significant portion of the costs you stand to incur is variable and only increases according to the amount of data you put in the data lake.

Identify your data sources
Next, you have to identify your data sources and the frequency you plan to add data to the data lake. Once you identify your data sources, you have to decide whether to add the data sets as it is or clean and transform the data. It is also vital that you identify the metadata for individual types of data sets.

Establish processes and automation
Since most of your data sets are coming from different systems, which might belong to various departments in your business, you must establish an automation process for consistency.
Say, for example, your HR department publishes an employee satisfaction report after each annual survey. At the same time, your accounting department publishes monthly data on the payroll. In that case, you will need to automate the data sourcing processes since your operations require a higher frequency of data publishing.

This could involve everything from automating the extraction, transformation, and data publishing to the schema-less data repository. You could also automate some of the individual steps to make your employees’ workload a little easier to handle.
Ensure right governance
Once you have your data lake set up, you must ensure that it functions properly. This involves putting big data into the data lake and facilitating data retrieval for other systems to generate informed data-driven business decisions. If you don’t ensure proper governance, your data lake might end up as a data swamp with little to no use in the long run.
Using the data from the data lake
With the correct amount of related metadata, you will be able to collect data from your data lake. But, to do this, you will have to implement different processes with ETL (extract, transform, load) operations before you can use the data to drive various business decisions. This is where big data houses and big data visualization come in. If more processing needs to be done in different data sets from other systems, you can publish the data to a data warehouse. Alternatively, you can feed the data into a data visualization and analytic tool like AWS Quicksight[2] or Microsoft Power BI[3].
Once you’ve got a fully functional data lake providing helpful insight for your business. The key to an efficient data lake lies in continuous development. If you need help with that, the Addepto team is at your service! For starters, take a look at our big data consulting services. Then – drop us a line and tell us what we can do for you.
Category:



