
June 14, 2021
Speech AI – how to improve call center sales performance
Author:

Data scientist
Reading time:
10 minutes
Artificial intelligence is now present in almost every industry, and call center AI is not an exception. Nowadays, people can use this technology to improve or facilitate their daily work. In addition to the ability to learn and predict, artificial intelligence also improves the customer experience in combination with voice analytics.
And today, we are going to show you how to improve call center sales performance with speech AI analytics. We will explore how your company can become more efficient with the speech AI implementation. But before we get to our case study, let us tell you how speech AI can help your company.
Speech AI in call centers: how it can help your company?
AI improves the effectiveness of voice analytics as it learns from conversations and makes suggestions in real time. It minimizes guesswork during interactions and provides assistance to your employees when they receive unusual or difficult requests.
Improved performance
AI reduces call center operators’ overall workload and helps them to work more efficiently. It performs tasks instead of the agent in some cases, allowing them to solve more difficult problems that require human involvement. [7]
Virtual assistant
A virtual assistant in call centers AI answers basic questions and makes announcements for callers. Another important application of AI is that it provides recommendations. [7]
Real-time suggestions
The majority of clients that call the сontact center AI service are angry or irritated. The speech AI analyzes the client’s words and phrases. It then generates real-time offers to the agent to reduce this aggression. [7]
You may find it interesting – Artificial Intelligence for Image Recognition
Case Study: improving call center performance with speech AI
This case study is an attempt to show how one can use tools available for free to create a simple voice analytics tool in a short amount of time. Then, you will know more about how useful is speech AI implementation. There are lots of articles on the internet regarding business insight from analysing call recordings – the most thorough of which I find the composition from google: [1]
We can summarize by distinguishing the 3 main segments of the AI solution:
- Speaker diarization – we need to be able to tell the speakers apart, to figure out the call silence and speaker talk time. Those can help us to analyze sales agents’ performance and ultimately give them useful insights.
- Speech transcription – in order to examine the sentiment we need to obtain the text version of the conversation. This is where speech AI is necessary.
- Sentence by sentence sentiment – after assigning the speakers with their utterances we can check the emotions they conveyed due to speech AI. Repetitive negative emotions emerging on the client side, as well as the agent side are an obvious red flag.
Project repository on gitlab.com [2]
Speaker diarization
We will perform diarization using the pyannote [3] python module. It relies on deep neural networks and requires pytorch to work.
The recording I used here is from the test part of the AMI Corpus. [4] In words of its creators – The AMI Meeting Corpus is a multi-modal data set consisting of 100 hours of meeting recordings. It is important to make sure the recording you choose will follow some criteria:
- at least two speakers present
- PCM 16-bits, mono, 16kHz, Wav format
- it was not a part of the training corpus
If you are using some of the free audio available online the last requirement is not obvious to follow. I personally chose the AMI corpus test set, because the model authors openly said they did not include it in the model’s training set.
Diarization pipeline
Aiming to keep things simple we will use a pretrained model bundled with the module. After installing the module we load the diarization pipeline
![]()
and it is pretty straightforward to obtain times when speakers change.

Depending on your machine it can take a couple of minutes. With GPU it happens immediately. We want to extract the exact times each of the speakers is talking and split the underlying audio file. Then we will transcribe each of the resulting utterances and estimate its sentiment.
In the diarization results we can sometimes see the same speaker’s utterances happening one after the other.

It probably has to do with a bit of silence between sentences – and in our case there is no need to work with those independently. We will merge those.

Finally we need to cut the original sample into the speaker’s utterances. For that I used ffmpeg python API. If you are using GPU – it might be best to shut down the jupyter kernel now and free the VRAM. Otherwise you might run out of it in the next step.
Speech transcription
For the transcription we can use NVidia’s newest tool – Jarvis framework. It is the hardware bottleneck of this case study – as it requires a Linux machine with GPU. Jarvis is deployed as a container which is why you need to have nvidia-docker installed. Assuming those criteria are met we can install the Jarvis framework.
For those of us who do not have an Nvidia account – we will need to sign up for free. After that we will be granted an API token, which will allow us to install the Nvidia NGC CLI tool used for downloading the resources. Fortunately it is not much of a hassle.
Jarvis speech skills
Following the quick-start-guide [5] we download Jarvis replacing the version number with the latest available:

and initialize
![]()
Before going further it might be necessary to change the config to limit the number of downloaded models. All the models loaded can take up to 14 GB VRAM which is why unless you own a GPU monster, you might want to cut to the bare essentials. Let’s open the config.sh file and comment out every model besides Jasper Offline w/ CPU decoder. After that we should be able to run the Jarvis server.
![]()
and the Jarvis client, which will throw us into the docker container.
![]()
You should expect to see something like this:
![]()
Now is a good time to transfer our test voice recordings to the client server. You can do that using the
![]() command. We have lots of small audio files, so in order to save some time, you can use an inline bash script:
command. We have lots of small audio files, so in order to save some time, you can use an inline bash script:
![]()
Once it’s there we want to run the jupyter notebook (in –allow-root mode). If you are running this on a remote machine – remember to forward the machine’s localhost to a port you want to use to access the notebook. (e.g.)
![]() We will base our notebook on the Jarvis_speech_API_demo to be found on the client server. You can download the notebook to see the whole code.
We will base our notebook on the Jarvis_speech_API_demo to be found on the client server. You can download the notebook to see the whole code.


I use glob to find relevant audio files, the Jarvis interface to perform a transcription for each of them, and then we save them into separate text files. A couple of times the transcription was empty, which is why I surrounded the code with the try-except statement. Remember to copy the results back into your main machine, as the jarvis client will disappear after you exit the ssh shell.
Sentiment analysis
We are going to use a pre-trained BERT model available on huggingface.co [6] It is very easy to use and returns the sentiment of a given sentence as a fraction of positive/negative/neutral sentiment.

After performing the sentiment analysis let’s save a .csv with our results.

Let’s move to the visualisation notebook and check what we’ve got. I liked the way Google proposed visualization in a similar case. [1]

So, we will try to do something similar. We have three indicators of sentiment, therefore, instead of mapping that into one value we will try to visualize all of the information. A non-overwhelming way to do that would be with a grid of pie charts.

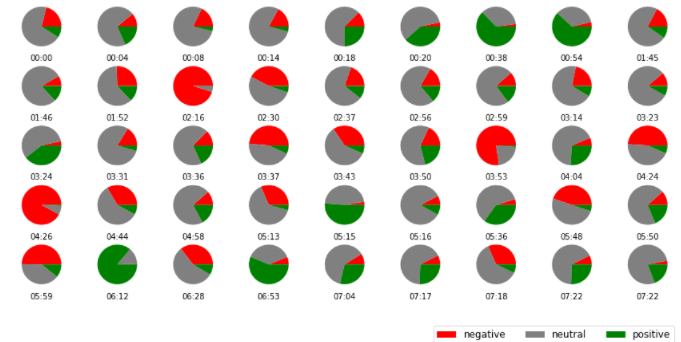
Let’s do a sanity check – there apparently are some negative feelings about the sentence in 2:16. What was it?
I mean. And you don’t want to I hate i hate looking at a control and seeing a million tiny little buttons with tiny little words saying what they all do and just. S sitting there searching for the tale text button.
Well that certainly is a frustrated user! What about the positivity in 6:12?
I’m right, okay we’ve got half an hour before the next meeting so we are going to go off and do individual things. Hi, I think that’s probably about it. And then we’ll come back to ease again yeah and I get to do another fantastic partment.
Seems like a positive note at the end of the meeting.
Retrieving other features
Speaker talk time
This one actually requires no more coding, as we have all we need from the speaker diarization part. We just need to calculate the intervals, group by speaker and sum up.

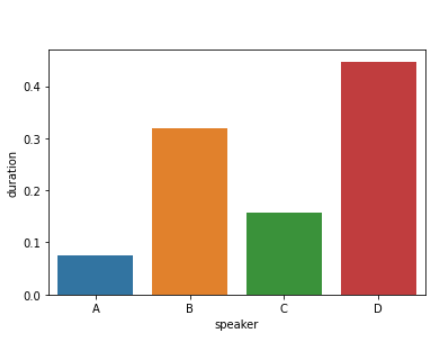
Speaker D was the most active here.
Call silence
There are a couple of ways to measure call silence. We could measure the volume, and deem everything lower than a threshold to be noise. Or we could use one of the silence detecting modules.
But in order to have a metric consistent with what we have so far, I decided to use previously obtained speakers’ talk duration and subtract it from the length of the whole audio file. After running
![]()
I know the original recording duration was 07:29.
![]()
which is around 23 seconds.
Summary
Relying heavily on existing frameworks and models, and adding a couple lines of code ourselves, we were able to sketch a simple tool for analysing calls. Solutions for professional use are not developed so quickly. There is still lots of space for improvements on every stage of this project:
- in planning – regarding choosing more features;
- in development – like fine tuning the models and in solution deployment – using the whole Jarvis server even though the fastest, isn’t optimal!
Still, we can see how easy it is nowadays to use free pre-baked machine learning blocks to create a new value.
Today, every interaction creates a data point that companies can use to better understand their consumers. Speech AI is a powerful tool that can help your business get a competitive advantage and perform at a higher level. To begin using speech AI and voice analytics in your contact center AI, your company should first create a single source of reliable data for all data. Addepto is a professional AI consulting company. If you need help with implementing speech AI in your business, do not wait to contact us!
References
- Cloud Google. Visualize speech data with Speech Analysis Framework. URL: https://cloud.google.com/architecture/visualize-speech-data-with-framework.
- Githab.com. AI voice analytics. URL: https://gitlab.com/addepto-public/ai-voice-analytics-public
- Github.com. Pyannote audio. URL: https://github.com/pyannote/pyannote-audio.
- Groups.inf.ed.ac.uk. Welcome to the AMcICorpus. URL: https://groups.inf.ed.ac.uk/ami/corpus/.
- Nvidia.com. Quick Start Guide. URL: https://docs.nvidia.com/deeplearning/jarvis/user-guide/docs/quick-start-guide.html.
- Hugginface.co. Twitter Roberta Base Sentiment. URL: https://huggingface.co/cardiffnlp/twitter-roberta-base-sentiment.
- Contactpoint360.com. How AI and Speech Analytics Can Improve Customer Experience. URL: https://contactpoint360.com/how-ai-and-speech-analytics-can-improve-customer-experience/. Accessed June 15, 2021.
Category:




