
April 15, 2020
Data Lake Architecture
Author:

Reading time:
5 minutes
Today’s efficient data lake architecture should be more like a data management platform able to process big data (structured and unstructured data) while providing speed, consistency, and security at a reasonable cost.
As explained in all traditional sources, a data lake is a central repository of the organization’s data, nevertheless of its type. But the second and most important part of data lake implementation might be omitted at the first glance – the need and possibility to take valuable insights from this data.
Every business decision is driven by the willingness to generate additional profits, either by generating personalized recommendations or another way round by reducing the churn rate. Therefore, storing all data as-is without or with limited further usage is not a good business decision.
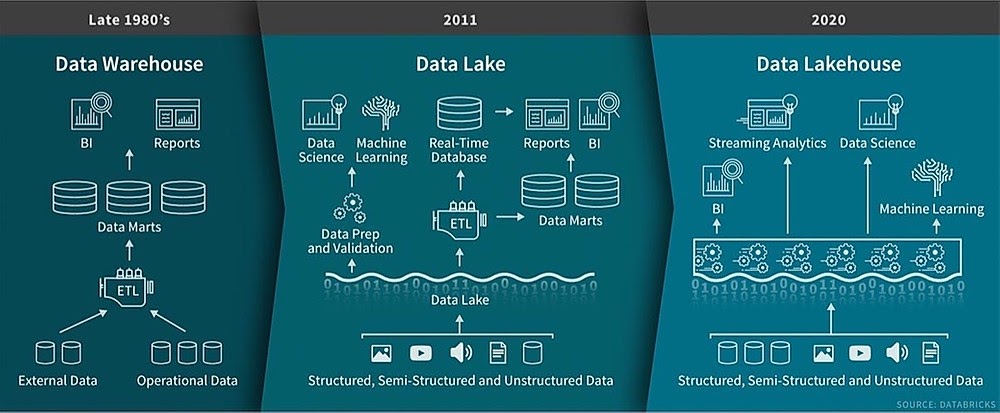
Efficient data lake architecture in 2020 is a data lakehouse?
Lakehouse is a newly appeared approach of creating a data lake that is supposed to be a single combined platform to store, analyze, and generate insights from the data. Multiple vendors and cloud providers are working towards such solutions.
Currently, we have Databricks with its Delta Lake and Apache Hudi which are closer to this definition than other solutions such as Snowflake or Azure Synapse.
Although they still do not cover the full range of functionality and are not fully flexible to be utilized in each use case, they already provide such functionalities as:
- audit history,
- data versioning,
- distributed computing and storage,
- ACID transactions,
- dynamic schema evolution.
What are the key factors when planning data lake architecture?
Storage option
Data storage providers usually offer multiple options in terms of how frequently data will be accessed and in how many zones it will be replicated. When designing data lake architecture these properties will ensure better security and additional cost savings as infrequently data storage costs less.
Data Analytics Engine
Data lake architecture design should include services that are able to process all types of data stored in the data lake in order to prepare it for further usage by Data Scientists or BI tools. This can be a serverless tool querying raw data on data lake directly (eg AWS Athena) or complete platform with its own compute resources and storage layer (eg features of Lakehouse we discussed earlier – Databricks, Apache Hudi).
The choice of tools depends on the user’s case and further data usage: we can create a complex cluster on AWS EMR with heavy data pipelines or just use AWS Glue and Athena for ad-hoc querying raw data. As a minimum set of features, such a system should:
- allow for concurrent work on the data by multiple users,
- have access restriction policy for separate users/groups of users,
- cost-effective enough maintaining speed and scalability at the same time.
Typically such an engine will be responsible for ETL processes (for both batch and streaming data), cleansing and data consistency validation, running interactive queries by users and testing machine learning models.
Ideally, it should also either support a user-friendly interface for non-technical business analysts for ad-hoc queries or integrate with tools that can provide it.
Output data of such an engine should be stored in the data lake thus minimizing costs and providing flexibility as per its further usage by other services or tools.
BI & AI
Ideally, modern data lake solution should be able to connect to the BI tool directly and use its own computing resources (eg Apache Spark) to display data and update dashboards.
Lack of an OLAP intermediary between Data Lake and BI tool can help to significantly reduce costs but might be too slow for users in case of bulky dashboards and a huge amount of data. Especially if such a BI tool will be connected to the flat file on data lake and will use resources of BI tool to prepare visualizations.
To optimize direct connection to flat files or analytics platform, data should be stored on multiple levels resulting in small final files/tables which will contain aggregated and prepared for a given dashboard information. Such a final layer of aggregated data is similar in its concept to the traditional Data Warehouse which also stores aggregated and selected data.
Multiple layers can be created by using modern data lake solutions such as Delta Lake or Apache Hudi during ETL jobs when incrementally updating historical tables with raw data and later be based on them.
As data should be used to generate insights, there should be a possibility to run and test various machine learning models to validate hypotheses. Data Scientists should be able to quickly prepare data and test ML models in the language they are used to, such as Python or R.

Data Catalog & Metadata
In big data, even the metadata itself can be “big data”. Therefore, modern data lake architecture should handle petabyte-scale tables with numerous partitions.
While leveraging the full potential of data in the organization it is important to know what this information is about and where it is coming from. For this purpose, a Data Catalog comes in, which can be a separate tool (eg AWS Glue) or included in the Data Analytics platform described above. One of the benefits of the separate tool is that information can be also shared with other services.
Data Lake Architecture – Security
Taking into account the sensitivity of data and a fact that multiple teams will be reaching for data in the data lake it is important to have a possibility to restrict access for separate user groups or even users.
Ideally, the role management feature should be part of all tools used to access data or they should integrate with a general access management tool of the cloud provider.
If you would like to find out how Data Engineering services can boost your business, contact Addepto!
Category:




